MINT Lernen mit CAS und KI
Hier findest du folgende Inhalte
Grundkompetenzen
In dieser Mikro-Lerneinheit lernst du, Computer Algebra Systeme für die symbolische oder numerische Berechnung mathematischer Aufgabenstellung kennen, speziell die Programme „Mathematica“, „Maple“ und „MATLAB“. Wir stellen „Python“ und „R“ als beliebte Programmiersprechen für numerische Berechnungen vor. Weiters stellen wir „GeoGebra“ und „Wolfram Alpha“ als beliebte CAS, für den ad-hoc Einsatz vor.
Wir erklären Stärken und Schwächen von keyword-basierter, wissensbasierer und sprachmodelbasierter Recherche speziell im MINT-Umfeld und weisen auf die Gefahren durch die Monopolisierung von Wissen hin.
2023 ist das Jahr in dem generative KI zu einer disruptiven Technologie wird. Wir gehen daher kurz auf die Historie der vier bisherigen industriellen Revolutionen ein, um auf Grund vergangener Umbrüche zu verstehen, ob es einen speziellen Grund zur Furcht vor den Auswirkungen der neuen Technologie gibt.
Mathematik Lernen mit Computer Algebra Systemen, Suchmaschinen und KI basierten Sprachmodellen
Mathematik Lernen mit Computer Algebra Systemen
Computer-Algebra-Systeme (CAS) sind Softwareprogramme, welche die symbolische oder numerische Berechnung mathematischer Aufgabenstellungen ermöglichen.
- Bei der symbolischen Berechnung werden mathematische Ausdrücke so umgeformt oder berechnet bis ein exaktes allgemeingültiges Resultat vorliegt, ohne dass dabei für die Variablen konkrete Werte eingesetzt werden.
- Bei der numerischen Berechnung wird die (näherungsweise) Lösung eines mathematischen Ausdrucks durch schrittweise Annäherung anhand spezifischer numerischer Werte iterativ ermittelt. Es werden dabei konkrete Zahlen für die Variablen eingesetzt und die resultierenden Ausdrücke ausgewertet. Auf die sehr rechenintensive numerische Berechnung greift man zurück, wenn eine symbolische Berechnung nicht sinnvoll möglich ist.
Beliebte Computer-Algebra-Systeme
- Mathematica wurde von Wolfram Research entwickelt und ist ein umfassendes CAS, das eine breite Palette an mathematischen und rechnerischen Fähigkeiten speziell für symbolische Berechnungen bietet.
- Maple ist ein leistungsstarkes CAS, das von Maplesoft entwickelt wurde. Es bietet umfangreiche Werkzeuge für symbolische Berechnungen, mathematische Visualisierung und Programmierung.
- MATLAB ist in erster Linie als numerische Rechenumgebung bekannt, umfasst aber über seine Symbolic Math Toolbox auch Funktionen für symbolische Berechnungen. Es kann durch Simulink ergänzt werden, welches speziell zur Modellierung von technischen, physikalischen oder finanzmathematischen Aufgabenstellungen optimiert ist.
Obige Computer-Algebra-Systeme werden in verschiedenen Bereichen eingesetzt, darunter Mathematik, Physik, Ingenieurwesen, Informatik und Bildung. Sie helfen Forschern, Wissenschaftlern, Ingenieuren und Studenten bei der Durchführung komplexer Berechnungen, der Erforschung mathematischer Konzepte und der Lösung komplizierter mathematischer Probleme.
Bei den oben genannten CAS handelt es sich um kommerzielle Software deren Vollversion auf Grund der Anschaffungskosten für Nutzer mit begrenzten Budgets kaum zugänglich sind. Die Software ist nicht für ad-hoc Einsätze gedacht, da sie eine umfangreiche Einarbeitung erfordern.
Beliebte Programmiersprachen für numerische Berechnungen
- Python als eine weit verbreitete und lizenzlos zugängliche Programmiersprache, die sich leicht erlernen und für numerische Berechnungen verwenden lässt, speziell um große Datenmengen zu sammeln, zu strukturieren, zu analysieren und zu visualisieren. NumPy- und SciPy-Bibliotheken bieten einen umfangreichen Satz numerischer Funktionen und Algorithmen, einschließlich linearer Algebra, Optimierung, Interpolation und mehr. Bei rechenintensiven Aufgaben kann Python im Vergleich zu kompilierten Sprachen langsamer sein. Obwohl NumPy und SciPy leistungsstark sind, bieten sie möglicherweise nicht das gleiche Leistungsniveau wie spezialisierte numerische CAS-Systeme
- R ist eine beliebte Sprache für statistische Berechnungen und Datenanalysen mit umfangreichen Paketen und Bibliotheken. Es bietet eine breite Palette an Statistikfunktionen und Visualisierungsmöglichkeiten. R verfügt über eine starke Community und eine Fülle an Ressourcen zum Lernen und zur Unterstützung. Für allgemeine numerische Berechnungen, die über Statistik und Datenanalyse hinausgehen, ist R möglicherweise nicht so gut geeignet wie spezialisierte numerische CAS-Systeme.
Beliebte Computer-Algebra-Systeme für ad-hoc Einsätze
- GeoGebra ist vor allem als dynamische Mathematiksoftware bekannt, die verschiedene mathematische Darstellungen integriert, darunter Geometrie, Algebra, Analysis und Statistik. Es bietet Benutzern eine Plattform zum Erstellen und Bearbeiten geometrischer Objekte, zum Plotten von Funktionen und zum Durchführen symbolischer Berechnungen mithilfe des integrierten CAS. GeoGebra legt Wert auf interaktives Lernen und Visualisierung und ist daher bei Pädagogen und Studenten beliebt.
Mit den CAS-Funktionen von GeoGebra können Benutzer symbolische Berechnungen durchführen, beispielsweise Ausdrücke vereinfachen, Gleichungen lösen, Ableitungen finden und Integrale auswerten. Allerdings ist die CAS-Funktionalität im Vergleich zu dedizierten CAS-Tools eingeschränkt. Auch die Möglichkeiten komplexe numerische Berechnungen durchzuführen können auf Grund der zugrundeliegenden Spezialisierung nicht mit Wolfram Alpha oder Wolfram Mathematik mithalten. GeoGebra‘s CAS ist in eine umfassenderen mathematischen Visualisierungs- und Explorationsfunktionen integriert und ermöglicht es Benutzern, symbolische Berechnungen mit dynamischen geometrischen Konstruktionen und Visualisierungen zu verbinden. - Wolfram Alpha ist eine rechnergestützte Wissensmaschine, die darauf ausgelegt ist, Fragen zu beantworten und detaillierte Informationen zu einem breiten Themenspektrum bereitzustellen. Es beinhaltet ein leistungsstarkes CAS, das über traditionelle mathematische Berechnungen hinausgeht und ein breites Spektrum an Bereichen abdeckt, darunter Mathematik, Naturwissenschaften, Ingenieurwesen, Finanzen, Linguistik und mehr. Wolfram Alpha kann komplexe mathematische Operationen verarbeiten, sein Anwendungsbereich geht jedoch weit über die reine Mathematik hinaus.
Das CAS von Wolfram Alpha kann anspruchsvolle Berechnungen durchführen, die symbolische Manipulation, Gleichungslösung, Analysis, lineare Algebra, Statistik und mehr umfassen. Es bietet umfassendes integriertes Wissen und Algorithmen, die es ihm ermöglichen, komplexe Probleme in verschiedenen Disziplinen zu lösen. Im Gegensatz zu GeoGebra konzentriert sich Wolfram Alpha in erster Linie auf die Bereitstellung detaillierter Antworten und Erklärungen auf der Grundlage von Benutzeranfragen und nicht auf interaktive Erkundungen oder dynamische Visualisierungen.
Zusammenfassend lässt sich sagen, dass sowohl GeoGebra als auch Wolfram Alpha CAS-Funktionen bieten, GeoGebra sein CAS jedoch in eine umfassendere interaktive Mathematiksoftware integriert und dabei den Schwerpunkt auf visuelles Erkunden und Lernen legt. Im Gegensatz dazu ist Wolfram Alpha eine umfassende rechnerische Wissensmaschine, die neben ihren vielen Funktionen auch ein robustes CAS umfasst und als Werkzeug zum Erhalten detaillierter Antworten und Erklärungen in zahlreichen Bereichen dient.
Mathematik Lernen mit Hilfe von Suchmaschinen
Lernen mit Keyword basierten Suchmaschinen mittels organischer Treffer
Keyword basierte Suchmaschinen wie Google, Bing, Yahoo oder Ecosia durchforsten mit Hilfe eines Web-Crawlers zyklisch die ihnen zugänglichen Teile vom Internet und erstellen einen Index, der für jedes Schlüsselwort die relevanten Webseiten auflistet. Da Google 2022 einen Anteil von 95% der Suchanfragen im deutschen Sprachraum hatte, werden wir uns im Folgenden auf die Google Terminologie beschränken.
Sucht ein Nutzer der Suchmaschine nach einem bestimmten Schlüsselwort – z.B.: „Binomialkoeffizient“, werden auf der SERP (Search Engine Result Page) nach einem (geheimen) Ranking-Algorithmus aus dem Index die blauen Links auf die relevanten Webseiten ausgegeben. Man spricht dabei von organischen Suchtreffern. Klickt der Suchende den Link an, landet er auf der entsprechenden Website eines Inhalteanbieters irgendwo auf der Welt. Da mehr als ein Treffer angeboten wird, bleibt die Meinungsvielfalt gewahrt.
2012 haben die keyword-basierten Suchmaschinen bezüglich der Strukturierung von Daten aufgerüstet. Oberhalb der organischen Treffer gibt Google auf der SERP, abgesehen von bezahlter Werbung, mehrere Boxen aus, deren Inhalt von Google generiert wird. D.h. Google verlinkt nicht mehr auf externe Inhalte, sondern generiert die Inhalte selbst. Die Quellen werden möglichst unauffällig angegeben und es ist nicht die Absicht von Google, dass Nutzer zum eigentlichen Inhalteanbieter weitersurft. Der Nutzer bleibt im Ökosystem von Google und es fällt kaum mehr Traffic für externe Webseiten an, die Meinungsvielfalt bleibt auf der Strecke.
- Direkt Answer, beantwortet einfache Suchanfragen, die über ein gigantischem Suchvolumen verfügen direkt, z.B.: "km Meilen". Der Nutzer bleibt im Google Ökosystem.
- Knowledge Panel bzw. Informationen aus dem Knowledge Graph, damit werden die auf verschiedenen Webseiten gefunden Informationen automatisch von Google zusammengefasst. Die Nutzer erhalten einen schnellen Überblick über allgemeine Themen, ohne auf externe Webseiten zu surfen. Hier werden ab 2023 wohl KI generierte Texte den Nutzer noch stärker zum Verweilen im Google Ökosystem verleiten.
- Featured Snippets, damit werden Auszüge aus einer durch Favicon und URL grundsätzlich identifizierbaren externen Webseite in Form einer Antwort auf die sehr konkrete Suchanfrage zusammengefasst. Trafficstarke Featured Snippets bringen viel organischen Traffic auf die Website des Inhalte-Erstellers. Hier werden ab 2023 wohl KI generierte Texte den Nutzer noch stärker zum Verweilen im Google Ökosystem verleiten.
- People Also Ask - Boxen, damit werden ähnliche Fragen beantwortet, die für den Nutzer ohne dessen Zutun die Suchanfrage verfeinern oder leicht abwandeln.
D.h. der Nutzer erhält eine erste oberflächliche und natürlichsprachige Antwort auf seine Suchabfrage bereits direkt durch Google, und zwar ganz oben auf der Trefferseite, noch vor den organischen Treffern. Der Nutzer "erspart" es sich dadurch auf die der Antwort zugrunde liegende Website zu surfen, was den Webseiten, welche die Inhalte aufwendig erstellt haben, um die Besucher und die damit verbundenen Vermarktungsmöglichkeiten bringt. An dieser Stelle sei vor einem Informationsmonopol durch Google, Bing, Yandex und Baidu gewernt!
Der Betrieb eines Indexers ist extrem teuer, daher gibt es weltweit nur 4 große Suchindizes (Google und Bing aus den USA; Yandex aus Russland bzw. den Niederlanden und Baidu aus China) die auf Grund ihrer Dominanz das Potential haben, die gesellschaftliche Willensbildung zu beeinflussen. Daher fördert die EU derzeit den Aufbau von einem europäischen Suchindex.
Das Training einer KI und deren Betrieb in einem Rechenzentrum sind ebenfalls extrem teuer, sodass es auch hier vor einem Informationsmonopol gewarnt werden muss.
Lernen mit wissensbasierten semantischen Suchmaschinen
Wissensbasierte semantische Suchmaschinen wie Wolfram Alpha suchen nicht nach einzelnen Schlüsselwörtern, sondern nach deren Bedeutung („Notable people born in Vienna“ wird zerlegt in „City=Vienna“ & „notable people born in city“) und nützten dabei durch „Data Curators“ händisch ausgewählte vertrauenswürdige Datenquellen, etwa von Statistischen Zentralämtern. Es kommt kein Indexer zum Einsatz.
Als Ausgabe erhält der Nutzer keine Links auf die Datenquellen wie bei Google, aber auch keinen Text in natürlicher Sprache wie bei ChatGPT, sondern ein Set an strukturierten Daten.
Bei der Suchfunktionalität von Wolfram Alpha handelt es sich um ein wissensbasiertes System, welches formalisierte Regeln und Logiken verwendet, um Fragen faktenbasiert zu beantworten. Der Nachteil dieses Ansatzes ist, dass die Suchmaschine komplex formulierte sprachliche Anfragen nicht verarbeiten kann und nur auf Fragen aus ausgewählten Wissenschaften eine Antwort liefern kann.
Mathematik Lernen mit KI basierten Sprachmodellen
KI-basierte Sprachmodelle wie ChatGPT von OpenAI oder Gemini (ehemals Bard) von Google wurden vorab mit gigantischen Textmengen trainiert. Sie nützen neuronale Netze, um Beziehungen zwischen einzelnen Worten und Texten zu erfassen und darauf aufbauend, basierend auf Wahrscheinlichkeiten und Modellen von Wortabfolgen, neue Texte zu erzeugen und diese dann in natürlicher Sprache auszugeben.
Während ChatGPT einen Text schreibt, evaluiert es auf der Basis eines komplexen Sprachmodells mit Milliarden an Parametern vor jedem neuen Wort, welche Wörter mit der größten Wahrscheinlichkeit auf den bisher geschriebenen Satzteil folgen sollten, um letztlich eine sinnvolle Abfolge von Sätzen zu ergeben.
Für mathematische Anwendungen bedeutet dies, dass ChatGPT die Summe aus 2+3 nicht eigenständig errechnen kann, sondern darauf angewiesen ist, das Resultat in den Trainingsdaten zu finden. Ist das nicht der Fall, fängt ChatGPT an zu raten!
Andererseits kann ChatGPT mathematisches Grundlagenwissen, welches in den Trainingsdaten umfangreich enthalten ist, sehr gut an die konkrete Fragestellung des Nutzers in dessen natürlicher Sprache angepasst wiedergeben. Z.B.: „Wobei nützt mir der Binomialkoeffizient?“
Durch die Sprachmodelle werden Features Snippets, Knowledge Panel und People Also Ask – Boxen obsolet.
Obwohl die Sprachmodelle mit Hilfe von Büchern sowie wissenschaftlichen Arbeiten trainiert wurden und auch auf den Indexer von schlüsselwortbasierten Suchmaschinen (Google, Bing,..) zugreifen können, bleibt dem Nutzer die Herkunft der Daten verborgen.
In den Trainingstexten liegen also zugleich die Stärken und Schwächen der KI-basierten ChatBots. Sind die dort enthaltenen Daten falsch oder trendig (z.b. vorurteilsbehaftet) so schlägt dies auf die Antworten durch.
Hinweis auf die Gefahr der Monopolisierung von Wissen
So begeistert Lernende über diesen Durchbruch bei Recherchetools auch sein mögen, so sei dennoch vor Missbrauch gewarnt:
Im Oktober 2022 hat der Tech-Milliardär Elon Musk Twitter – nunmehr X – um unvorstellbare 40 Milliarden Euro gekauft und nach seinen ganz persönlichen Vorstellungen dieses weltumspannende Informationsnetzwerk umgestaltet.
Im September 2023 kamen Gerüchte auf, Elon Musk als Gründer und CEO von SpaceX, dem Mutterunternehmen von Starlink, hätte persönlich angeordnet das Satellitenkommunikationsnetzwerk in der Umgebung der russisch besetzen Krim Halbinsel abzuschalten, um einen potenziellen Angriff der Ukraine auf die dort stationierte russische Flotte zu verhindern.
Diese beiden Beispiele zeigen, welchen realen Einfluss bereits heute ein einzelner Mensch auf die freie Meinungsbildung und auf den Verlauf eines Krieges hat.
Stellen wir uns vor, ein anderer Tech-Milliardär hatte vergleichbaren Einfluss auf die Trainingsdaten von ChatGPT. Stellen wir uns weiter vor, er würde beispielsweise daran glauben, dass Gott die Erde wörtlich in sieben Tagen erschaffen hat und damit Darwins Theorie von der Evolution negieren. Könnte er diese Meinung auf Grund seines Aktenanteils durchsetzen und Darwins Theorie fortan nicht mehr zu den Traingsdaten gehören, so würde auch ChatGPT diese fragwürdige Schöpfungstheorie mit Nachdruck gegenüber seinen Nutzern vertreten.
Risiko systematischer Fehlinformation bei Suchindex basierte Recherche beim Lernen:
Die Nutzung von schlüsselwortbasierten Suchmaschinen wie Google zur Informationsbeschaffung beim Lernen ist uns heute bestens vertraut. Der Nutzen ist unbestritten, die größte Gefahr liegt in der weltweiten Konzentration des Angebots auf nur 4 Betreiber von Suchindizessen (Google, Bing, Yandex und Baidu).
Bislang gibt der Nutzer einen Suchbegriff als Anfrage ein und erhält als Antwort eine Liste mit relevanten Links. Aus dieser Vielzahl an möglichen Antworten sucht er sich dann die passende Antwort selbst heraus. Auf Grund der Impressumspflicht weiß der Nutzer, von welchem Menschen die Antwort stammt.
Risiko systematischer Fehlinformation bei Sprachmodell basierte Recherche beim Lernen:
Seit der Einführung von ChatGPT, dem Sprachmodell von Open AI, basiert die Anfrage nicht mehr auf einem Schlüsselwort oder Satzteil, sondern auf mehreren ausformulierten Sätzen, mit denen die Such-Intention genau abgegrenzt werden kann. Die Antwort ist aber keine Vielzahl an Verweisen auf individuelle Websites, sondern ein eloquent ausformulierter Text aus mehreren Sätzen bzw. Absätzen, jedoch ohne Bezug auf die zugrunde liegenden Quellen. Der Nutzer kann auch um eine Korrektur, Vereinfachung oder Vertiefung der Antwort bitten und erhält so, wie bei einem Dialog zwischen Menschen, eine kontextbezogene Antwort. Super!
Weniger Super: Die Antwort ist allerdings nicht einmal ein „best-off“ aller (ungenannten) Quellen, sondern – man lasse sich das auf der Zunge zergehen – „Jene Abfolge von Worten, mit der höchsten statistischen Wahrscheinlichkeit, für eine sinnvoll formulierte Antwort“. ChatGPT kann 1+1 nicht (!) berechnen, es kann nur auf Grund von Trainingsdaten sagen, dass es statistisch wahrscheinlich ist, dass „1+1=2“ gilt. Sind die Trainingsdaten zudem nicht objektiv, sondern tendenziell (rassistisch, frauenfeindlich, politisch geschönt, verschwörerisch, …), so ist die Antwort ebenfalls nicht objektiv. Bei der indexbasierten Suche hingegen deckt die Liste an Links auf verschiedene Websites ein breites Meinungsspektrum ab.
Kommen Informationen in den Trainingsdaten nicht vor, so fabuliert ChatGPT. Sprachmodelle können grundsätzlich und für alle Zukunft gar nicht entscheiden, ob ihre Antwort richtig ist oder falsch ist, denn sonst müsste die KI bei der Bewertung der Anfrage über mehr Wissen verfügen als bei der Formulierung der Antwort.
Evolutionäre versus revolutionäre Entwicklungen im Bereich von Technologie
Generative KI gilt als eine disruptive Technologie, durch die die Erstellung von Texten, Musik, Bildern und Videos radikal verändert wird, indem menschliche intellektuelle Leistung durch maschinelle Leistung ersetzt wird.
Eine vergleichbare Entwicklung zu den anstehenden Veränderungen zufolge des breiten Einsatzes von KI im Beruf und Alltag, hat es mit dem Ersatz von manueller durch maschinelle Arbeit, also durch die Erfindung der Dampfmaschine, schon einmal gegeben. Zur besseren geschichtlichen Einordnung der aktuellen Herausforderungen, denen wir speziell seit dem Jahr 2023 zufolge des lawinenartigen Einsatzes von KI gegenüberstehen, beginnen wir daher mit einem kurzen Rückblick:
Während durch evolutionäre technologische Entwicklungen Produkte im Laufe der Zeit durch inkrementelle Verbesserungen kontinuierlich weiterentwickelt werden und dabei auf vertrauten Vorgängermodellen aufbauen (das neueste Automodell stellt eine Verbesserung des Vorgängermodells dar, das schon seinerseits eine Verbesserung des Vorgängermodells darstellte, …), führen revolutionäre Entwicklungen zu radikalen Veränderungen, welche die bestehende Paradigmen in Frage stellen und völlig neue Möglichkeiten und Risken schaffen.
Revolutionäre Entwicklungen stellen einen raschen dramatischen Umbruch dar und haben weitreichende Auswirkungen auf Wirtschaft, Technologie, Arbeitsmarkt und Gesellschaft. Die Weiterentwicklung von Innovationen zufolge revolutionärer technologischer Entwicklungen haben einen exponentiellen Charakter. Sie haben das Potential Produktivität sprunghaft zu steigern und damit punktuellen Wohlstand zu erzeugen, der jedoch oft zu Lasten von breiten Schichten an Erwerbstätigen geht, und neue Einkommensungleichheiten schafft.
Sie sind daher verbunden mit Ängsten vor sozialer und wirtschaftlicher Ungerechtigkeit, denen man durch Regulierung und Politik so entgegenwirken sollte, dass die Vorteile der neuen Technologien einer breiten Bevölkerungsschicht zugutekommen.
KI als General Purpose Technology und die vier bisherigen industriellen Revolutionen
Unter dem Ausdruck „General Purpose Technologies“ fasst man bisherige revolutionäre technologische Fortschritte zusammen, die auf Grund ihrer exponentiellen und globalen technologischen Umbrüche das Potential haben, tiefgreifende und weitreichende Veränderungen in Wirtschaft und Gesellschaft herbeizuführen. Beispiele für derartige General Purpose Technologies sind:
Dampfmaschine: (1770, Watt) Sie prägte die erste industrielle Revolution, in dem sie den Übergang von handwerklicher auf industrielle Produktion ermöglichte. Die Dampfmaschine revolutionierte durch die damit einher gehende Mechanisierung die Landwirtschaft, die produzierende Industrie und das Transportwesen.
Elektrizität: (1882, Edison) Sie prägte die zweite industrielle Revolution, weil elektrischer Strom den Transport und die Nutzung von Energie revolutionierte. Sie ermöglichte kostengünstige Motoren, Beleuchtung und die Fernkommunikation durch Telefon und Radio, wodurch sich der Lebensstandard breiter Bevölkerungsschichten erheblich verbesserte.
Digitalisierung: (1950, IBM bzw. 1990, Berners-Lee) Sie prägte die dritte industrielle Revolution, durch den Übergang von analogen zu digitalen Techniken. Lernende sind nicht mehr darauf angewiesen Bücher physikalisch in die Hand zu bekommen, sondern ganze Bibliotheken sind digital 24/7 verfügbar. Computer, das Internet, HTML-basierte Webbrowser, Keyword basierte Suchmaschinen mit Links auf organische Treffer revolutionierten die Art und Weise wie Menschen und Maschinen Informationen verarbeiteten, bereitstellten und teilten.
Erfolgten die ersten drei industriellen Revolutionen noch mit einem zeitlichen Abstand von jeweils 100 Jahren, erfolgt die vierte industrielle Revolution staccatoartig auf breiter Front und mit exponentieller Geschwindigkeit.
Vernetzung von gigantischen Datenmengen: (2010) Vor allem die Auswertung von Datenmengen, deren Umfang von Menschen nicht mehr erfasst werden kann, begründet die vierte industrielle Revolution: Big Data, IoT (Internet der Dinge), Maschinelles Lernen und darauf aufbauend KI (Künstliche Intelligenz; Englisch: AI), aber auch Augmented bzw. Virtual Reality (erweiterte Realität) und autonomes Fahren sind zu alltäglichen Buzzwords geworden.
Hinzu kommt der signifikante Ersatz von fossiler durch erneuerbare Energie im Rahmen des Kampfs gegen den Klimawandel, sowie der Einsatz von Biotechnologie basierend auf der Genomsequenzierung im Bereich der Medizin.
Schon den nächsten Urlaub geplant?
Auf maths2mind kostenlos auf Prüfungen vorbereiten!
Nach der Prüfung mit dem gesparten Geld deinen Erfolg genießen.
rgb(244,123,130)
Bild

Lektion 1: Grundlegende Bedienung von GeoGebra
In dieser Mikro-Lerneinheit verschaffen wir uns einen Überblick über die wesentlichen Bedienelemente von GeoGebra. Wir lernen die Hauptansichten kennen, die vier ansichtenspezifischen Werkzeugleisten, die Menüleiste, die beiden Eingabezeilen und die virtuelle Tastatur. Klicke die einzelnen Icons mal an und erfahre mehr über die vielfältigen Möglichkeiten des Programms.
Zuerst verschaffst du dir zuerst einen Überblick darüber, welche Aufgabenstellungen mit GeoGebra überhaupt gelöst werden können. Mit welcher Eingabe man dann eine konkrete Aufgabenstellung löst, weiß man - bei häufig wiederkehrenden Aufgabenstellungen - auswendig, oder - bei selteneren Aufgabenstellungen – schaut man in der Dokumentation nach.
Die Hauptansichten
GeoGebra ist ein dynamisches Mathematikprogramm, welches bis zu 5 verschiedene Ansichten auf ein und dasselbe mathematische Objekt (z.B.: die Gleichung einer Geraden \(y = f(x) = k \cdot x + d\)) liefert. GeoGebra verbindet geometrischen Darstellungen („Grafik“) mit algebraische Ein- bzw. Ausgaben („Algebra“) und ermöglicht Parametervariationen mit Schiebereglern. Zusätzlich verfügt es über ein Computer Algebra System („CAS“), eine rudimentäre Tabellenkalkulation („Tabelle“) und ein Statistikmodul („Wahrscheinlichkeitsrechner“).
Bild

- In der Grafik-Ansicht kann man geometrische Objekte konstruieren. Parallel dazu erscheint die mathematische Beschreibung in der Algebra-Ansicht.
- In der Algebra-Ansicht kann man mathematische Objekte definieren. Parallel dazu erscheint die geometrische Konstruktion in der Grafik-Ansicht.
- In der CAS-Ansicht kann man Terme umformen, Gleichungen lösen sowie integrieren und differenzieren.
- In der Tabellen-Ansicht kann man Punktpaare zu Listen zusammenfassen um anschließend mit Hilfe der Regression die zugrundeliegende Funktionsgleichung zu ermitteln.
- Mit dem Wahrscheinlichkeitsrechner kann man Wahrscheinlichkeits- bzw. Dichtefunktionen und Verteilfunktionen berechnen.
Die Werkzeugleisten
Die Werkzeugleiste von GeoGebra verläuft horizontal am oberen Rand des Fensters. Sie ist zweigeteilt.
Bild

Im linken Bereich werden Icons angezeigt, welche Werkzeuge repräsentieren, die abhängig von der jeweiligen Ansicht sind. Klickt man auf eines der Werkzeuge, so werden unterhalb weitere, ähnliche Werkzeuge angezeigt.
Bild

Im rechten Bereich werden die Werkzeuge für „Rückgängig“, „Wiederherstellen“ und „Lupe“ angezeigt. Klickst du auf „Lupe“, kommst du automatisch auf die Online-Plattform mit zahlreichen kostenlosen Unterrichtsmaterialien. Zudem kann ganz rechts die Menüleiste ein- bzw. ausgeblendet werden.
Die Gestaltungsleisten
Jede Ansicht (Grafik, Algebra, 3D-Grafik, CAS und Tabelle) verfügt über eine eigne Gestaltungsleiste, mit der verschiedene Grundeinstellungen für
- die Ansicht selbst
- die in der Ansicht enthaltenen Objekte
verändert werden können.
Bild

Ein- und ausblenden kann man die Gestaltungsleiste rechts oben im Fenster der jeweiligen Ansicht.
Gestaltungsleiste der Grafik-Ansicht
Klickt man in der Grafik-Ansicht auf das Icon der Gestaltungsleiste so lassen sich folgende Einstellungen vornehmen:
- Achsen anzeigen oder verbergen
- Koordinatengitter anzeigen oder verbergen
- Standardeinstellungen der Koordinatenachsen wieder herstellen
- Punkte an den Ecken der Koordinatengitter fangen
- Einstellungen öffnen
- Weitere Ansichten einblenden
Klickt man hingegen auf ein bestimmtes Icon der Werkzeugleiste, dann kann man die Eigenschaften (Farbe, Strichstärke, Linienart, Beschriftung,...) eines konkreten Objekts (Punkt, Gerade, Vektor, Kreis,...) verändern.
Sehr nützlich: Wenn man in der Grafik-Ansicht einmal den Überblick verloren hat, wo am Zeichenblatt sich überhaupt Inhalte befinden, kann man in der Gestaltungsleiste mittels dem Haus-Icon und dem Werkzeug mit dem "Dehnen-Pfeil" alle Inhalte sichtbar machen.
Bild

Gestaltungsleiste der Algebra-Ansicht
Klickt man in der Algebra-Ansicht auf das Icon der Gestaltungsleiste so lassen sich folgende Einstellungen vornehmen:
- Sortierung der Zeilen in der Algebra Ansicht wählen.
- Sortieren nach freien und abhängigen Objekten
- Sortieren nach dem Typ des Objekts (Punkte, Vektoren,...)
- Sortieren der Objekte nach Ebenen, in denen sie konstruiert wurden
- Sortieren nach der Reihenfolge der Konstruktion
- Einstellungen öffnen
- Weitere Ansichten einblenden
Bild

Gestaltungsleiste der CAS-Ansicht
Klickt man in der CAS-Ansicht auf das Icon der Gestaltungsleiste so lassen sich folgende Einstellungen vornehmen:
- Textformatierungen der Formelinhalte je Zeile, z.B.: Farbe, Fettschrift, Schrägschrift
- Einstellungen öffnen
- Weitere Ansichten einblenden
Bild

Gestaltungsleiste der Tabellen-Ansicht
-
Textformatierungen der Formelinhalte je Zeile, z.B.: Fettschrift, Schrägschrift, Text-Bündigkeit
-
Hintergrundfarbe
- Einstellungen öffnen
- Weitere Ansichten einblenden
Bild

Gestaltungsleiste der 3D-Grafik-Ansicht
Klickt man in der 3D-Grafik-Ansicht auf das Icon der Gestaltungsleiste so lassen sich folgende Einstellungen vornehmen:
- Achsen anzeigen oder verbergen
- Koordinatengitter anzeigen oder verbergen
- Standardeinstellungen der Koordinatenachsen wieder herstellen
- Punkte an den Ecken der Koordinatengitter fangen
- Drehung der Ansicht starten bzw. stoppen
- Blickrichtung auf die 3D-Darstellung wählen: Grundriss, Aufriss bzw. Kreuzriss
- Art der Projektion wählen: Parallelprojektion, Perspektive mit Fluchtpunkt, 3D für rot-grün-3D-Brille, Schrägprojektion
- Einstellungen öffnen
- Weitere Ansichten einblenden
Bild

Die Menüleiste
Die GeoGebra Menüleiste wird mit dem Icon aus 3 Strichen, ganz rechts in der oben horizontal verlaufenden Werkzeugleiste, ein- und ausgeblendet. Sie enthält Menüs mit denen man Dateien öffnen oder abspeichern kann, mit der man die Hauptansichten wählen kann, oder mit denen man globale die Einstellungen ändern kann.
Bild

Die Eingabezeilen
Mit Hilfe der Eingabezeile und Befehlen kann man die algebraische Repräsentation eines mathematischen Objekts eingeben bzw. ändern. Die GeoGebra Eingabezeile kann über die Menüleiste und das Ansicht-Menü ein- bzw. ausgeblendet werden. Sie befindet sich dann am untersten Rand vom Fenster.
Bild
")
Ist die Algebra-Ansicht aktiviert, dann wird dort eine Algebra-Eingabezeile angezeigt, wenn die oben beschriebene GeoGebra Eingabezeile ausgeblendet ist.
Bild

Die virtuelle Tastatur
Wenn man GeoGebra erstmalig startet, dann erscheint links die Algebra-Ansicht und rechts die Grafik-Ansicht. Darunter wird eine virtuelle Tastatur angezeigt, die mit der Maus bedient wird.
Bild

Sollte die virtuelle Tastatur mal unsichtbar werden, dann klickt man auf das "+" in der Algebra-Eingabezeile und wählt "Ausdruck". Dann wird die virtuelle Tastatur eingeblendet.
Bild

Bei der virtuelle Tastatur kann zwischen unterschiedlichen Tastatur-Layouts umgeschaltet werden.
Bild

Bild

Bild

Bild

Bild

Bild

Bild

Lektion 2: Dateihandling und Dateneingabe in GeoGebra
In dieser Mikro-Lerneinheit verschaffen wir uns einen Überblick über den "Datei" - Eintrag in der Menüliste und über diverse programmspezifische Anforderungen an die Eingabe.
Zuerst verschaffst du dir zuerst einen Überblick darüber, wie du eine neue oder bestehende GeoGebra Datei mit der Datei-Endung .ggb öffnest, bearbeitest und wieder abspeicherst. Weiters ist es unbedingt erforderlich zu wissen, wie man die diversen Eingaben korrekt eintippen muss, damit sie von GeoGebra korrekt verarbeitet werden können.
"Einstellungen" - Eintrag in der Menüleiste
Als Erstes sollte man einige globale Einstellungen vornehmen. Die Sprache, die Anzahl der Nachkommastellen, ob Objekte in der Grafik-Ansicht sichtbar benannt werden und die Schriftgröße (12pt) wählt man in der Menüleiste unter "Einstellungen".
Bild

„Datei“ – Eintrag in der Menüleiste
Beschäftigen wir uns zunächst damit, wie wir ein GeoGebra-Arbeitsblatt öffnen und speichern können.
-
„Neu“ erstelle ein neues leeres Arbeitsblatt
-
„Öffnen“ macht dasselbe wie ein Klick auf die „Lupe“ in der Werkzeugleiste:
-
„online“: In der Hauptansicht vom GeoGebra Fenster wird die GeoGebra-Online-Plattform mit zahlreichen kostenlosen Unterrichtsmaterialen angezeigt und man kann eine Datei auswählen, öffnen, bearbeiten und abspeichern.
-
„lokal“: Über den Button ganz links oben im Fenster kann man auf lokal am Computer gespeicherte Dateien zugreifen
-
-
„Speichern“ ermöglicht das Abspeichern vom gesamten Arbeitsblatt in einer GeoGebra-Datei vom Typ .ggb.
-
„Bild exportieren“ ermöglicht es die Grafik-Ansicht als pixelbasierte Bilddatei vom Typ .png abzuspeichern.
-
„Teilen“ ermöglicht es, zuvor auf der GeoGebra-Online-Plattform abgespeicherte Arbeitsblätter, über soziale Netzwerke oder als direkter Link weiterzugeben.
-
„Herunterladen als…“ ermöglicht das Abspeichern des aktuell sichtbaren Ausschnitts der Grafik-Ansicht, in verschiedenen Dateiformaten wie .png, .svg oder .pdf.
Will man mehr Einfluss – z.B. einen transparenten Bildhintergrund - auf die Parameter der Bilddatei haben, dann empfiehlt sich der Befehl „ExportImage“.
z.B.: ExportImage("filename", "beispiel_4410_1.svg", "type", "svg", "transparent", "true") -
„Druckvorschau“ ermöglicht das Ausdrucken des aktuell sichtbaren Ausschnitts der Grafik-Ansicht
Bild

Anforderungen an die Eingabe:
Mit Hilfe der Eingabezeile und Befehlen kann man die algebraische Repräsentation eines mathematischen Objekts eingeben bzw. ändern. Dabei sind folgende Regeln zu beachten:
- Dezimalzahlen erfordern die englische Schreibweise, d.h. das Komma wird als Punkt geschrieben. Beispiel: ½ als 0.5 nicht als 0,5
- Hochzahl einer Potenz erzeugt man mit der „Dach-Taste“, also etwa 2x durch 2^x
- Fakultät wird als n! geschrieben und ist das Produkt aller natürlichen Zahlen größer Null und kleiner gleich n
- Binomialkoeffizient n über k wird als nCr(n,k) geschrieben und besagt, wie viele Möglichkeiten es gibt, k Elemente aus einer Menge von n Elementen auszuwählen
- Permutation ohne Zurücklegen nPr(n,k) besagt, wie viele Möglichkeiten es ohne Zurücklegen gibt, k Elemente aus einer Menge von n unterscheidbaren Elementen auszuwählen
- Komplexe Zahl im CAS: Die Eingabe muss in der Form (a+bi) erfolgen, nicht aber als (a+ib).
- Punkte werden mit Großbuchstaben eingegeben: A=(2,2)
- Vektoren werden mit Kleinbuchstaben eingegeben v=(1,1,2)
- Listen werden mit dem Kleinbuchstaben l und einer Zahl innerhalb einer geschwungenen Klammer eingegeben: l1={1,2,3} oder l2={4,5,6}. Am einfachsten erzeugt man Listen in der Listenansicht.
- Matrizen werden mit dem Kleinbuchstaben m und einer Zahl innerhalb einer geschwungenen Klammer als Liste von Listen eingegeben: m1= {{1, 2, 3}, {4, 5, 6}} oder m1={l1,l2}
- Eulersche Zahl \(e\) darf nicht als Buchstabe „e“ eingegeben werden, sondern wird
- entweder als Sonderzeichen über die virtuelle Tastatur (im Bereich 123 zu finden) eingegeben
- oder mittels „Alt + e“ über die Tastatur
- Kreiszahl Pi wird
- durch das Wort pi oder Pi eingegeben
- oder als Sonderzeichen über die virtuelle Tastatur (im Bereich 123 zu finden) eingegeben
- oder mittels „Alt P“ über die Tastatur
- Imaginäre Einheit i darf nicht als Buchstabe „i“ eingegeben werden, sondern wird
- entweder als Sonderzeichen über die virtuelle Tastatur (im Bereich f(x) zu finden) eingegeben
- oder mittels „Alt + i“ über die Tastatur
- Unendlich-Zeichen \(\infty \) wird
- entweder als Sonderzeichen über die virtuelle Tastatur eingegeben
- durch das Wort infinity oder Infinity eingegeben
- oder mittels „STRG + U“ über die Tastatur.
- Zuweisung := vs Gleichung = In der CAS-Ansicht werden Variable und Terme mit einem den Gleichheitszeichen vorgesetzten Doppelpunkt „:=“ zugewiesen, nicht so in der Algebra-Ansicht
- CAS-Eingabe: f(x):=2x^2
- Algebra-Eingabe: f(x)=2x^2
- Mal-Rechenzeichen „*“ der Multiplikation muss in der CAS-Ansicht verpflichtend in der Form „*“ eingegeben werden, nicht so in der Algebra-Ansicht
- CAS-Eingabe: a*(b+c)
- Algebra-Eingabe: a(b+c)
- Brüche werden in Form einer Division angeschrieben, wobei sowohl Zähler als auch Nenner in runde Klammern gesetzt werden sollten.
- Variablen existieren nur ein Mal innerhalb eines Arbeitsblattes. Es kann der Variablen in einer nachfolgenden CAS-Eingabe kein neuer Wert zugewiesen werden. Variablen, die in der Algebra-Ansicht definiert wurden, werden in der CAS-Ansicht nicht erneut dargestellt, können aber verwendet werden.
- Funktionen kann man durch den Funktionsterm einzugeben, man kann aber auch y= oder f(x)= voran setzen.
- Betragsfunktion gibt man als abs(..) ein, wobei die Zahl zwischen runden Klammern gesetzt wird.
- Signumfunktion liefert Vorzeichen, die man mit Hilfe der Signum-Funktion sign(x) ermittelt
- Liefert +1 für positive Zahlen, -1 für negative Zahlen und 0 für null
- Rundungsfunktionen erhält man mit Hilfe
- round(x), wodurch auf die nächste ganze Zahl gerundet wird
- ceil(x), wodurch auf die nächste ganze Zahl aufgerundet wird
- floor(x), wodurch auf die nächste ganze Zahl abgerundet wird
- Wurzel zieht man mit Hilfe von sqrt(x)
- Logarithmen berechnet man mit Hilfe von ln(x), log(x) bzw. mit log10(x) oder log2(x)
- Winkelfunktionen berechnet man mit sin(x), cos(x), tan(x),…
- Umkehrung der Winkelfunktionen liefern mit
- arcsind(x) das Ergebnis in Grad
- arcsin(x) das Ergebnis in Radianten
Unterschied freie und abhängige Objekte
- Freie Objekte (z.B.: 2 Punkte A, B) hängen nicht von der Position oder vom Wert bereits zuvor erstellter Objekte ab. Werden freie Objekte über ihre "Einstellungen" fixiert, können sie nicht mehr gezogen und damit auch nicht mehr in ihrer Position am Zeichenblatt verändert werden.
- Abhängige Objekte (z.B.: die Strecke AB) hängen von der Position oder vom Wert bereits zuvor erstellter freier Objekte ab. Löscht man das zugrunde liegende freie Objekt, so löscht man auch das abhängige Objekt.
Statische und dynamische Texte
Die Eingabemaske für Texte wird über die Werkzeugleiste und das Icon "ABC Text" eingegeben. Über "Erweitert" kann man 4 Kartei-Reiter (Vorschau, GeoGebra-Symbol, Griechischen Zeichensatz und vordefinierte LaTeX Formeln) anzeigen.
- Statischer Text wird über die Tastatur eingegeben und ist von Objekten und Änderungen an Objekten unabhängig. Statischer Text kann in Form von ASCII Code oder als LaTeX-Code eingegeben werden. Während mit ASCII Code die von der Tastatur vertrauten Buchstaben und Ziffern und einige darüber hinausgehende Sonderzeichen eingegeben werden können, kann man mit LaTeX-Code ganze Formeln (samt Wurzel- und Integralzeichen oder Brüchen) eingeben.
- Dynamischer Text wird mit Hilfe der im Kartei-Reiter mit dem GeoGebra-Symbol enthaltenen Objekten erstellt.
- Statischer und Dynamischer Text zusammen ermöglichen Texte mit Koordinaten zu vereinen.
Bild

Geogebra Binomial (Befehl)
- Binomial( <Anzahl der Versuche>, <Erfolgswahrscheinlichkeit> )
- Mit dem Befehl Binomial (n, p) erzeugt man in der Grafik-Ansicht ein Balkendiagramm.
- Der Parameter n steht dabei für die Anzahl der von einander unabhängigen Bernoulli-Versuche.
- Der Parameter p steht für die Erfolgswahrscheinlichkeit pro Versucht
Beispiel
- Gegeben:
- n=20
- p=0,9
- Gesucht:
- Balkendiagramm der Binomialverteilung
- Ausführung:
- Syntax: Binomial( <Anzahl der Versuche>, <Erfolgswahrscheinlichkeit> )
- Geogebra Grafik-Ansicht: Binomial(20, 0.9)
- Anmerkung: x-Achse auf 0 .. 22 skalieren; y-Achse auf 0 .. 0,5 skalieren
- Lösung:
- Wir erhalten ein Balkendiagramm der Binomialverteilung.
- Der höchste Balken entspricht dem zugehörigen Erwartungswert \(E(x) = \mu \)
Beispiel
- Gegeben:
- n=20
- p=0,9
- Gesucht:
- Erwartungswert \(E(x) = \mu \) der Binomialverteilung
- Standardabweichung \(\sigma\) der Binomialverteilung
- Ausführung:
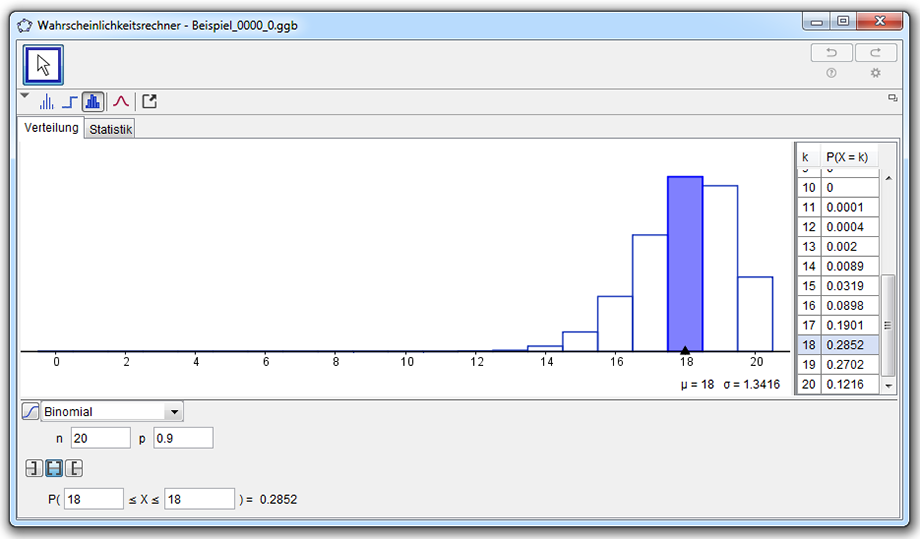
- Geogebra → Ansicht → Wahrscheinlichkeitsrechner
- Im Feld für die Verteilung von Normal auf → Binomial umstellen
- n=20 und p=0.9 eingeben
- Die Klammerausdrücke können unbeachtet bleiben
- Lösung:
- Wir erhalten ein Balkendiagramm der Binomialverteilung.
- Wir erhalten den zugehörigen Erwartungswert zu \(E(x) = \mu = 18\)
- Wir erhalten die zugehörige Streuung zu \(\sigma = 1,3416\)
Bild
Geogebra InversNormal (Befehl)
- InversNormal[ <Mittelwert>, <Standardabweichung>, <Wahrscheinlichkeit> ]
- Mit dem Befehl InversNormal (μ, σ , P] berechnet man jene Zufallsvariable X, welche die gegebene Wahrscheinlichket P als Fläche unter der Gauß'schen Glockenkurve besitzt.
Beispiel
- Gegeben:
- Erwartungswert μ = 1005 mm
- Standardabweichung σ = 5 mm
- Fläche = 0,025 bzw. Wahrscheinlichkeit P = 2,5%
- Gesucht:
- Zufallsvarialble X
- Ausführung:
- Syntax: InversNormal[ <Mittelwert>, <Standardabweichung>, <Wahrscheinlichkeit> ]
- Geogebra - CAS Ansicht: InversNormal[1005, 5, 0.025] → X=x1 = 995,25
- Lösung
- Für die Zufallsvariable X=x1 = 999,25 mm beträgt bei einer μ = 1005 mm und σ = 5 mm verteilten Normalverteilung die Wahrscheinlichkeit 2,5% bzw. die Fläche unter der Gauß'schen Glockenkurve 0,025
Beispiel
- Gegeben:
- Erwartungswert μ = 1005 mm
- Standardabweichung σ = 5 mm
- Fläche = 0,95 bzw. Wahrscheinlichkeit P = 95%
- Gesucht:
- Ermitteln Sie dasjenige um μ symmetrische Intervall, in dem 95 % der Zufallswerte liegen.
- Ausfühung:
- untere Grenze: Fläche links von der unteren Grenze: \(\dfrac{{1 - 0,95}}{2} = 0,025\)
- Syntax: InversNormal[ <Mittelwert>, <Standardabweichung>, <Wahrscheinlichkeit> ]
- Geogebra - CAS Ansicht: InversNormal[1005, 5, 0.025] → x1 = 995,25
- obere Grenze: Fläche links von der oberen Grenze: \(\dfrac{{1 - 0,95}}{2} + 0,95 = 0,975\)
- Syntax: InversNormal[ <Mittelwert>, <Standardabweichung>, <Wahrscheinlichkeit> ]
- Geogebra - CAS Ansicht: InversNormal[1005, 5, 0.975] → x2 = 1014,75
- untere Grenze: Fläche links von der unteren Grenze: \(\dfrac{{1 - 0,95}}{2} = 0,025\)
- Lösung:
- Das symmetrische Intervall, in dem mit einer Wahrscheinlichkeit P=95% alle Zuvallsvariablen X einer μ = 1005 mm und σ = 5 mm verteilten Normalverteilung liegen, lautet: [995,2; 1 014,8]
- Grafische Darstellung
-
Der Befehl mit der Syntax: Normal[μ, σ, x, false] erzeugt eine Darstellung der Wahrscheinlichkeitsdichtefunktion der Normalverteilung f
-
Geogebra Grafik-Ansicht: Normal(1005, 5, x, false)
-
-
Der Befehlt mit der Syntax: Integral(<Funktion>, <untere Grenze>, <obere Grenze>) berechnet das bestimmte Integral der Funktion f zwischen unterer und oberer Grenze und schattiert die Fläche über die integriert wurde.
-
Geogebra Grafik-Ansicht: Integral(f, 995.25, 1014.75)
-
-
Schon den nächsten Urlaub geplant?
Auf maths2mind kostenlos auf Prüfungen vorbereiten!
Nach der Prüfung mit dem gesparten Geld deinen Erfolg genießen.
rgb(244,123,130)
Bild
Geogebra Normal (Befehl)
- Normal[ <Erwartungswert>, <Standardabweichung>, <Wert der Variablen x1> ]
- \(P\left( {X \le x_1} \right)\) einer \({\rm{N}}\left( {\mu ,\sigma } \right)\) Normalverteilten Zufallsvariablen X berechnen
- Mit dem Befehl Normal[μ, σ , x1] berechnet man die Wahrscheinlichkeit P dafür, dass eine Zufallsvariable X kleiner oder gleich einem Grenzwert x1 ist. Das Resultat entspricht der Fläche unter der Gauß'schen Glockenkurve, welche links von x1 liegt.
Beispiel
- Gegeben:
- Erwartungswert μ = 12,000 mm
- Standardabweichung σ = 0,06 mm
- untere Grenze x1 = 11,96 mm
- obere Grenze x2 = 12,04 mm
- Gesucht:
- Wahrscheinlichkeit, dass eine Zufallsvariable X zwischen einer unteren x1 und einer oberen x2 Grenze liegt
- \(P\left( {{x_1} \le X \le {x_2}} \right)\) einer \({\rm{N}}\left( {\mu ,\sigma } \right)\) -verteilten Zufallsvariablen X berechnen
- Ausführung:
- Syntax: Normal[μ, σ , x2] - Normal[μ, σ , x1]
- Geogebra Algebra-Ansicht: Normal[12, 0.06, 12.04] - Normal[12, 0.06, 11.96] → (0,7475 - 0,2525 =) 0,495
- Lösung
- Die Wahrscheinlichkeit, daß ein μ = 12,000 mm und σ = 0,06 mm verteilter Zufallswert zwischen x1 = 11,96 mm und x2 = 12,04 mm liegt, beträgt 49,5%
- Grafische Darstellung
- Der Befehl mit der Syntax: Normal[μ, σ, x, false] erzeugt eine Darstellung der Wahrscheinlichkeitsdichtefunktion der Normalverteilung f
- Geogebra Grafik-Ansicht: Normal(12, 0.06, x, false)
- Der Befehlt mit der Syntax: Integral(<Funktion>, <untere Grenze>, <obere Grenze>) berechnet das bestimmte Integral der Funktion f zwischen unterer und oberer Grenze und schattiert die Fläche über die integriert wurde.
- Geogebra Grafik-Ansicht: Integral(f, 11.96, 12.04)
- Der Befehl mit der Syntax: Normal[μ, σ, x, false] erzeugt eine Darstellung der Wahrscheinlichkeitsdichtefunktion der Normalverteilung f
Satz von Thales
Interaktive Illustration auf GeoGebra.org anzeigen
Bewege den Punkt P entlang vom Halbkreis und beobachte wie sich die beiden Winkel immer zu 90° aufsummieren.
Exponentialfunktion
Interaktive Illustration auf GeoGebra.org anzeigen
- Regler a: Verändere die Basis
- Regler c: Verändere den Faktor
Natürliche Exponentialfunktion
Interaktive Illustration auf GeoGebra.org anzeigen
- Regler \(\lambda\): Entscheidet über Wachstum oder Zerfall
- Regler N0: Entscheidet über Startwert
Schon den nächsten Urlaub geplant?
Auf maths2mind kostenlos auf Prüfungen vorbereiten!
Nach der Prüfung mit dem gesparten Geld deinen Erfolg genießen.
rgb(244,123,130)
Bild
Wolfram Alpha ein erster Eindruck
Wolfram Alpha (Pro)
Wolfram Alpha (Pro) ist eine kostenlose Website, welche einzelne Suchabfragen basierend auf kuratierten Daten und CAS-Funktionalität miteinander verbindet. Die Benutzeroberfläche weist einen Suchslot auf, in den man die jeweilige Abfrage, losgelöst von vorherigen Abfragen, entweder in englischer natürlicher Sprache oder als mathematischen Term gemäß der Wolfram-Language eingibt. Die Ausgabe erfolgt als Set von strukturierten Daten.
Die Basisversion Wolfram Alpha ist kostenlos, die Pro Version bietet zusätzlich Schritt-für-Schritt Lösungen, ermöglicht Downloads und verfügt über einen Aufgaben-Generator, dafür ist sie kostenpflichtig.
Wolfram Alpha Notebook Edition
Wolfram Alpha Notebook Edition ist kostenpflichtig als Desktop- bzw. als Online-Variante verfügbar. Die Alpha Notebook Edition ist als separates Produkt und als Teil von Mathematica erhältlich. Die Wolfram Alpha Notebook Edition erweitert die Funktionalität von Wolfram Alpha Pro, indem es aufeinander aufbauende Verarbeitungen ermöglicht, während Alpha Pro auf eine „one-Shot“ Abfrage/Antwort limitiert ist. Die Notebook Edition basiert auf Mathematica, erlaubt aber weitgehend eine Eingabe in englischer natürlicher Sprache, dh man muss die Wolfram-Language nicht unbedingt beherrschen.
Wolfram Mathematica
Wolfram Mathematica ist kostenpflichtig als Desktop- bzw. als Online-Variante verfügbar. Mathematica ist eine professionelle Software für Mathematik auf Universitäts-Niveau und erfordert einiges an Einarbeitungszeit. Die Notebook Edition ist auch Teil von Mathematica.
In dieser Mikro-Lerneinheit lernst du die Recherche mittels der KIs „OpenAI ChatGPT“, „Google Gemini“, bzw. „Microsoft Bing / Copilot“ kennen.
Zunächst machen wir uns mit dem Begriff „Künstliche Intelligenz“ vertraut und zeigen, dass sich unser Verständnis, was künstliche Intelligenz ist, im Laufe der Zeit verändert.
Maschinelles Lernen ist der Unterbau vieler KIs, ebenso deren Trainingsdaten. Wir beschreiben den Unterschied zwischen KIs ohne und mit maschinellem Lernen, sowie die Ansätze mit überwachtem, nicht überwachtem und bestärkendem maschinellem Lernen. Wir erklären wie maschinelles Lernen mit Hilfe von neuronalen Netzen und Deep Learning ohne menschliches Zutun funktioniert.
Wir erklären, was generative KIs sind, und dass die Mensch-Maschine-Schnittstelle auf Natural Language Processing und dieses wiederum auf Large Language Modellen basiert. Danach arbeiten wir den Unterschied zwischen Algorithmus und Modell heraus.
Als Verarbeitungseinheiten eines LLMs lernen wir Prompt, Token, Token-Vektor sowie Chat samt Kontext kennen. Anschließend gehen wir auf die beiden sprachbasierte generative KIs „ChatGPT“ und „Bard“ ein, indem wir die Stärken und Schwächen der unterschiedlichen Architekturen „GPT“, „LaMDA“ und „Gemini“ beschreiben.
Wir zeigen, wie man die jeweilige KI startet und bedient, und gehen auf deren Einschränkungen im Bereich Mathematik näher ein.
Recherche und Lernen mit den KIs ChatGPT und Bard
Künstliche Intelligenz und ihre Komponenten
Der Begriff künstliche Intelligenz (KI, englisch: Artificial Intelligence bzw. AI) wird gerne verwendet, wenn IT-Systeme Entscheidungen treffen, für die Intelligenz erforderlich ist.
Dabei verändert sich im Laufe der Zeit unsere Einschätzung darüber, was wir als künstliche Intelligenz wahrnehmen oder eben nicht, und zwar indirekt proportional zur Vertrautheit mit der jeweiligen Technologie.
Ein Beispiel zur zeitabhängigen Wahrnehmung von künstlicher Intelligenz
- Vor 10 Jahren hat man Navigationssysteme im Auto noch als „intelligent“ bezeichnet.
- Heute versteht man sie eher rational als eine Kombination aus GPS-Signalen samt genauer Zeitmessung, einer Straßendaten-Datenbank, einem Algorithmus aus der Graphentheorie zur Berechnung des kürzesten Weges (etwa der Dijkstra Algorithmus) und eventuell noch Echtzeit-Verkehrsfluss-Informationen, sowie einer Mensch-Maschine Schnittstelle, die heute oft das vertraute und allgegenwärtige Smartphone mit der Anwendung Google Maps ist.
Das ehemals intelligente System ist 10 Jahre später zu einem dummen Rechenknecht degeneriert.
Heute, 02.2024, versteht man die Weiterentwicklung der Navigationssysteme, nämlich selbstfahrende Autos, als intelligente Systeme.
Unter einer künstlichen Intelligenz versteht man ein Computerprogramm, welches genau definierte Aufgaben ausführen kann, für die normalerweise menschliche Intelligenz erforderlich wäre. Die Betonung liegt auf „genau definierte Aufgaben“: Ein Schachcomputer auf Großmeisterniveau kann nicht unbedingt auch die Schachfiguren am Brett greifen, anheben, bewegen und wieder abstellen, was jedes Kind kann.
Maschinelles Lernen
Maschinelles Lernen ist eine Schlüsseltechnologie für Systeme der künstlichen Intelligenz, gewissermaßen ihr Unterbau. Als maschinelles Lernen bezeichnet man jenen Prozess, bei dem das Verhalten eines Computerprogramms nicht durch einen menschlichen Programmierer festgelegt wurde, sondern das Programm – die KI - aus Trainingsdaten lernt, darin enthaltene Muster selbsttätig erkennt, um darauf aufbauend Aufgaben erfüllen zu können.
Maschinelles Lernen bewährt sich besonders dort, wo der menschlichen Intelligenz keine Regeln in Form von Ursache – Wirkungszusammenhängen zugänglich sind, oder die Datensätze unüberschaubar groß sind.
Es gibt KIs mit und solche ohne maschinelles Lernen.
KIs ohne maschinelles Lernen, Expertensystem
Bei KIs ohne maschinelles Lernen, sogenannten regelbasierten KIs, werden die Algorithmen vom Entwickler so programmiert, dass sie bestimmte Aufgaben erfüllen. Beispiele für solche regelbasierten Algorithmen sind Regression, Klassifikation, Clustering, Zeitreihen.
Wenn eine KI darauf abzielt das menschliche Wissen eines Experten, sogenanntes Domänen-Knowhow zu modellieren und zu replizieren, dann spricht man von einem Expertensystem.
KIs mit maschinellem Lernen
Bei KIs mit maschinellem Lernen findet das Computerprogramm die spezifischen Regeln durch selbstständiges Ausprobieren und Benchmarken an einem vorgegebenen Ziel selbst. Durch maschinelles Lernen können also Regeln gefunden werden, die dem Programmierer zuvor nicht zugänglich waren.
Maschinelles Lernen umfasst also die Fähigkeit des Programms Erfahrungen zu machen, in dem es Regeln sucht und findet, um die Zielerfüllung eigenständig zu verbessern, dazu passt es während eins Lernvorgangs die Parameter des Modells an. Beispiele für solche Algorithmen sind Entscheidungsbäume, k-nächste Nachbarn, Support-Vektor-Maschinen (SVM) und neuronale Netze.
Neuronale Netze
Neuronale Netze sind eine von mehreren Techniken des maschinellen Lernens, die speziell gut dafür geeignet ist, komplexe, nicht lineare Beziehungen in Trainingsdaten zu modellieren. Neuronale Netze bestehen aus einer Eingangs- und einer Ausgangsschicht von Neuronen. Zwischen diesen beiden Schichten liegen die sogenannten verborgenen Schichten. Der Informationsfluss zwischen den Neuronen erfolgt über sogenannte Kanten, denen wiederum ein Gewicht (gedanklich eine Verstärkung bzw. Dämpfung) zugeordnet ist. Das maschinelle Lernen erfolgt vorwiegend durch Anpassung der Gewichte in den Kanten, solange bis das neuronale Netz die zum Eingangssignal entsprechenden Ausgangssignale liefert. Die Gewichtung der Kanten erfolgt durch kontinuierliche Justage und ist nicht durch einen Algorithmus – den ein Programmierer vorgibt - beschreibbar.
Neuronale Netze sind also eine Grundtechnologie von KI-Systemen mit maschinellem Lernen. Ihr Aufbau aus, miteinander verbundenen, künstlichen Neuronen ist vom Aufbau des menschlichen Gehirns inspiriert. Ihre Aufgabe ist es Informationen zu verarbeiten und Muster in Daten zu erkennen.
Deep Learning
Beim Deep Learning besteht das neuronale Netz, neben der obligaten Eingangs- und Ausgangsschicht aus vielen zusätzlichen Schichten, die es ermöglichen komplexere Modelle abzubilden.
Bedeutung von Trainingsdaten und Big Data für maschinelles Lernen
Für maschinelles Lernen sind neben Hardwareanforderungen an die verarbeitende IT noch qualitativ hochwertige Trainingsdaten erforderlich, geeignete Algorithmen und die Definition eines klar beschriebenen Ziels. Interessant ist, dass die Lernalgorithmen teils schon seit Jahrzehnten bekannt sind.
Da aber die Trainingsdaten umfangreich sein müssen, ging der Durchbruch beim maschinellen Lernen, Hand in Hand mit den Fortschritten bei der Verarbeitung von Big Data.
Der Nutzung von Trainingsdaten gehen zwei Arbeitsschritte voraus:
- Datenquellen müssen zugänglich gemacht werden und die daraus resultierenden Daten müssen digital erfasst werden
- In den erfassten Daten allenfalls enthaltene Fehler müssen korrigiert werden und die Daten müssen so aufbereitet werden, dass sie für den eigentlichen maschinellen Lernprozess automatisiert und im Falle von Wiederholungen unverändert zugänglich sind.
Die Beschaffung von Trainingsdaten ist daher sehr aufwändig und kostenintensiv. Nachfolgend 2 öffentlich zugängliche Quellen für Trainingsdaten:
- Wikipedia wird gerne für Trainingsdaten herangezogen. Dabei wird gerne übersehen, dass die Artikelverteilung keineswegs ausgewogen ist. Beispiele dafür können hier nachgelesen werden:
- Veröffentlichungen des Übersetzungszentrums für die Einrichtungen der EU werden gerne als Trainingsdaten für Übersetzer verwendet, da dort professionelle Übersetzungen innerhalb der 24 Amtssprachen der EU vorliegen.
Je nach der spezifischen Aufgabe und der Art der verfügbaren Trainingsdaten können verschiedene Lernmethoden verwendet werden, um optimale Ergebnisse zu erzielen.
Überwachtes maschinelles Lernen (Supervised Learning)
(dem Algorithmus werden Daten mit „richtigen“ Lösungen zur Verfügung gestellt)
Beim überwachten Lernen teilt man die Trainingsdaten in 2 Kategorien: 70% Lerndaten und 30% Testdaten.
- Lerndaten: Anhand der Lerndaten lernt der Algorithmus Vorhersagen zu treffen, da ihm die richtige Lösung bereits mitgegeben wird.
- Testdaten: Anhand der Testdaten wird anschließend der Grad der Zielerreichung ermittelt. Daher spricht man von „überwachtem“ Lernen.
Beispiel:
- Ein KFZ-Sachverständiger verfügt über Trainingsdaten, die aus 1.000 Fotos von PKWs samt Typbezeichnung bestehen.
- 700 Fotos samt Typbezeichnung werden dem Algorithmus als Lerndaten zur Verfügung gestellt.
- Den Testdaten, bestehend aus den restlichen 300 Fotos, die dem Algorithmus jedoch ohne Typbezeichnung vorgelegt werden, muss der Algorithmus die Typbezeichnung auf Grund der gelernten Regeln selbsttätig zuordnen.
- Der KFZ-Sachverständige überprüft anschließend den Erfolg in Prozent der richtigen Antworten.
- Bei überwachtem Lernen sind sowohl Eingabemuster als auch die gewünschten Ausgabemuster bekannt.
- Das neuronale Netz vergleicht das berechnete Ausgabemuster mit dem gewünschten Ausgabemuster und passt die Gewichtungen zwischen den Neuronen entsprechend an.
- Dieses Verfahren ist effizient und schnell.
- Es erfordert das Vorhandensein von Daten mit der „richtigen“ Antwort, sogenannte gelabelte Daten, die mit menschlicher Expertise erstellt wurden. Ausreißer bzw. atypische Daten, die nicht in den Lerndaten enthalten waren, verursachen Probleme.
- Es wird häufig für Aufgaben wie Klassifikation und Regressionsprobleme verwendet.
Unüberwachtes maschinelles Lernen (Unsupervised Learning)
(dem Algorithmus werden keine Daten mit „richtigen“ Lösungen zur Verfügung gestellt)
- Unüberwachtes Lernen erfolgt ohne Trennung zwischen Lern- und Testdaten. Dem Algorithmus werden also während des Lernens keine Vorlagen für „richtige“ Lösungen mitgegeben.
- Das Netzwerk muss eigenständig lernen, Muster in den Daten zu erkennen und in verschiedene Gruppen oder Kategorien einzuteilen, indem es Ähnlichkeiten bzw. Unterschiede zwischen den Mustern erkennt.
- Die Gewichtungen werden so angepasst, dass ähnliche Eingabemuster ähnliche Ausgaben erzeugen.
Beispiel:
- Ein KFZ-Sachverständiger verfügt über Trainingsdaten, die aus 1.000 Fotos von PKWs bestehen und die ohne weitere Angaben dem Algorithmus vorgelegt werden.
- Der Algorithmus versucht nun Muster in den Daten zu erkennen.
- Eventuell sortiert er die Autos nach KFZ-Typ, eventuell nach deren Farbe, eventuell nach Spuren von Unfällen, eventuell sortiert er auch nur die sehr seltenen Pick-Ups aus. Es kann sogar sein, dass sich die gefundenen Muster nicht interpretieren lassen, weil sie nicht zur Erlebniswelt des Sachverständigen passen.
- Der KFZ-Sachverständige muss anschließend entscheiden, ob die Sortierung für ihn einen praktischen Nutzen hat oder nicht.
- Da das Verfahren ohne gelabelte Daten auskommt, ermöglicht es die Entdeckung von neuen Zusammenhängen, die im Voraus nicht bekannt waren. Das kann aber auch negativ sein, wenn die erlernten Muster nicht für die vorgesehene Anwendung relevant sind, d.h. die KI entwickelt dann Lösungen, für die womöglich niemand das zugehörige Problem hat.
- Unüberwachtes Lernen wird oft beim Clustering angewendet. Es kann Musikvorschläge liefern oder Brustkrebs auf Grund von Strukturen in Bildern erkennen.
Bestärkendes maschinelles Lernen (Reinforcement Learning)
(dem Algorithmus wird positives oder negatives Feedback gegeben)
- Bestärkendes Lernen wird in Situationen eingesetzt, die sich permanent verändern
- Der Algorithmus führt verschiedene Aktionen aus und erhält für Versuch und Irrtum positives oder negatives Feedback, je nachdem ob seine Ausgabemuster richtig oder falsch sind.
- Er muss aber selbstständig die richtigen Ausgabemuster finden, indem er versucht das positive Feedback zu maximieren und das negative Feedback zu minimieren.
Beispiel:
- Ein Roboterarm mit Greifzange muss ein Wasserglas anheben, welches jedes Mal an einer anderen Stelle am Tisch steht. Dazu positioniert er über Motoren den Greifarm relativ zum Wasserglas.
- Es gibt eine positive Bewertung, wen er das Wasserglas hochhebt, ohne es zu zerbrechen.
- Es gibt eine neutrale Bewertung, wenn das Wasserglas nur vermeintlich hochgehoben wird, aber unversehrt stehen bleibt.
- Es gibt eine negative Bewertung, wenn das Wasserglas zerbricht.
- Dieser Lernprozess ist nicht so schnell wie das überwachte Lernen, aber er eignet sich für Situationen, in denen keine klaren Entscheidungskriterien vorhanden sind, wie etwa beim autonomen Fahren.
Unterscheidungsbasierte KIs
Unterscheidungsbasierte KIs können Beziehungen und Regeln finden und nutzen, von denen Existenz der menschliche Programmierer gar keine Ahnung hatte. Zudem können auch Aufgaben gelöst werden, für die es schwer ist, eine Schritt-für-Schritt Anleitung zu geben, etwa welches Lied einem Nutzer auf Basis der bisher gehörten Lieder als nächstes gefallen würde. Sie kommen in Spamfiltern, in der Bild- und Spracherkennung zum Einsatz und liefern Daten und Trainingsmaterial für generative KIs.
Generative KIs
Generative KIs lernen aus bestehenden Inhalten und erzeugen eigenständig neue Inhalte. Anwendungsbereiche dafür sind Text-zu-Bildgenerierung (Middourney, DALL-E, Stable Diffusion), Sprachgenerierung (ChatGPT, Gemini, Copilot),… Generative KIs generieren Text für die Interaktion mit Nutzern mittels conversational KIs.
Conversational AIs
Erfolgt das Dialogmanagement, also die Mensch-Maschine-Schnittstelle über einen Chat, so spricht man von einem conversational AI-System. Dieses ermöglicht es, mehrere aufeinanderfolgende Textein- und -ausgaben im Rahmen eines Gesprächsverlaufs (Chat) zu verwalten, um eine längere Konversation zu ermöglichen, ohne dass die KI den „roten Faden“ verliert.
Semantik
Semantik ist ein Begriff aus der Sprachwissenschaft und beschäftigt sich damit, wie in einer Sprache Bedeutung während einer Kommunikation auf Basis von Zeichen, Symbolen, Wörtern und Sätzen verstanden wird.
Betrachten wir den Satz: „Die Katze jagt die Maus“. Die Semantik beschäftigt sich damit, was die Worte bedeuten und in welcher Beziehung sie zueinanderstehen.
- Eine Katze ist ein beliebtes Haustier auf 4 Pfoten, welches über einen angeborenen Jagdtrieb verfügt und sich gerne von Nagetieren und Vögeln ernährt.
- Eine Maus ist ein anpassungsfähiges Nagetier, das sich von Pflanzen und Körnern ernährt und Katzen meidet.
- Jagen bedeutet, dass die Katze auf die Maus lauert, sie verfolgt, angreift, tötet und frißt.
Der Kontext, in dem dieser Satz zu sehen ist, besteht darin, dass ein Raubtier, welches ein beliebtes Haustier ist, kleine Nagetiere jagt, um sich von ihnen zu ernähren. Zu mindestens dort, wo es kein Kitekat zu fressen gibt ;-)
Mensch-Maschine Schnittstelle zwischen KI und Nutzer
Entscheidend für die Akzeptanz der auf künstlicher Intelligenz basierenden Anwendungen ist die Mensch-Maschine-Schnittstelle (MMI, Man-Machine-Interface).
Für die Kommunikation zwischen Anwender und KI haben sich besonders Natural Language Processing Systeme bewährt. Gesprochene oder geschriebene Sprache sind uns Menschen bestens vertraut und NLP-Systeme reduzieren die Hürden bei der Interaktion mit KI-Systemen und erhöhen, da sie intuitiv und effektiv nutzbar sind, die Akzeptanz von KI-Anwendungen.
Natural Language Processing (NLP)
Als Schnittstelle zwischen dem Menschen und der KI, also der sogenannten Mensch-Maschine-Schnittstelle (MMI), haben sich Natural Language Processing (NLP) Systeme bewährt.
NLP-Systeme sind darauf ausgerichtet, menschenähnliche Kommunikation in Textform zu ermöglichen. Die Kommunikation zwischen Menschen und Maschine kann z.B. in Form eines Chats erfolgen.
Semantik spielt in NLP-Systemen eine wichtige Rolle, denn deren Ziel ist es, die Bedeutung von Texten automatisch zu erfassen, zu analysieren und darauf zu reagieren.
Bei Chatbots dient NLP dazu, Fragen zu analysieren und präzise sinnvolle Antworten in Textform zu generieren. Der Chatbot stellt dabei die Mensch-Maschine-Schnittstelle auf Basis textueller Ein- und Ausgaben dar.
Für die simple maschinelle Übersetzung einzelner Phrasen aus wenigen Wörtern ist kein „Erinnerungsvermögen“ der NLP erforderlich.
Bei chatbasierte KIs, wie bei ChatGPT und Bard, wird das Erinnerungsvermögen in Token (Textfragmenten) gemessen. Es müssen hinreichend viele neuen Token generiert wird, damit der „rote Faden“ während des Chats nicht verloren geht und andererseits nur so wenige Token um das Ziel (die Antwort) erreichen zu können, ehe der Speicherplatz überläuft. ChatGPT-3.5 nennt selbst 4096 Token als Maximum für alle Ein- und Ausgabe zusammen, die während eines Chats anfallen.
Large Language Modelle (LLM)
Die bereits erwähnten Natural Language Processing (NLP) Systeme basieren wiederum auf Large Language Modellen. LLMs sind auf das Verständnis von natürlicher Sprache spezialisierte neuronale Netze, die, wenn sie über mehrere Hidden Layer verfügen, als Deep Learning bezeichnet werden.
Sprachmodelle sind eine mathematische Beschreibung dafür, wie natürlich-sprachige Sätze typischerweise aufgebaut sind. Sie funktionieren aber nicht regelbasiert, etwa auf der Basis von grammatikalischen Regeln und Wörterbüchern, sondern basieren auf statistischen Zusammenhängen über das gemeinsame Auftreten von Wörtern.
„An einem heißen Sommertag führte ich ein Glas Wasser zum Mund und nahm einen kräftigen ?????“. Vermutlich hat Ihr Gehirn den Satz – auf Grund von Erfahrungen und der damit verbundenen statistischen Wahrscheinlichkeit – schon vervollständigt. Denn wir haben seit unserer Kindheit gelernt, dass wir Menschen in diesem Kontext einen „Schluck“ nehmen und ganz sicher nicht einen Bissen oder gar einen Elefanten.
Bei einem LLM werden solche statistischen Zusammenhänge selbstständig anhand von riesigen Datenmengen auf Basis von Wahrscheinlichkeiten erlernt und durch künstliche neuronale Netze abgebildet.
Große Sprachmodelle (LLMs) wie ChatGPT und Bard wurden mit mehreren hundert Milliarden an Texten trainiert, wovon etwa Wikipedia weniger als 0,5% der Trainingsdaten ausmacht.
Nach dem Training können Texte kontextbezogen in natürlicher Sprache automatisiert gelesen und geschrieben werden.
Man sei sich auch der Gefahren von LLM bewusst!
Etwa in der Unterscheidung zwischen Wahrscheinlichkeit und Wahrheit: LLM erstellen Antworten auf Basis von aus Trainingsdaten gelernten Wahrscheinlichkeiten für sinnvolle Wortabfolgen, nicht aber auf Basis des zugrunde liegenden Wahrheitsgehalts. Durch diesen Ansatz neigen LLM bei Antworten systembedingt zum „Halluzinieren“ und „Schwafeln“.
Mist-rein → Mist raus: Von wesentlicher Bedeutung für die Qualität der Antworten eines LLM ist die Qualität der Trainingsdaten. Beinhalten die Trainingsdaten falsche, trendige oder diskriminierende Aussagen, darf man von der Antwort nichts Besseres erwarten. Darin liegt auch die Problematik LLM basierte KIs online auf das Internet zugreifen zu lassen. Nicht jeder ist mit der unentgeltlichen Nutzung seiner Daten durch KI-Betreiber einverstanden, und es kommen zunehmend „vergiftete“ Daten ins Netz. Dabei werden Daten absichtlich so verfälscht, dass eine KI in die Irre geführt wird und meinen einen Hund auf einem Bild zu identifizieren, wo eigentlich eine Katze abgebildet ist
In der Zensur von Daten: Wenn Trainingsdaten ausgewählt werden, entspricht dies einer Wissenskontrolle. Wenn die Trainingsdaten hingegen nicht ausgewählt werden, sondern frei aus dem Web stammen, besteht die Gefahr des Erlernens von Vorurteilen.
Themenfilter: Sowohl bei der Auswertung von Eingaben als auch bei der Ausgabe von Antworten arbeiten die Betreiber von LLMs mit Verbotslisten. Verbotslisten umfassen Wörter, Phrasen oder Muster, die von einem LLM nicht verarbeitet werden dürfen, um sicher zu stellen, dass keine unerwünschten, unangemessenen oder diskriminierende Inhalte erzeugt werden. Andererseits schränken Verbotslisten die Meinungsfreiheit ein und fördern Zensur.
Algorithmus
Ganz allgemein beschreibt ein Algorithmus mittels einer Handlungsvorschrift, wie aus einer Eingabe eine Ausgabe wird.
Eingabe → Verarbeitung gemäß Algorithmus → Ausgabe
Ein Kochrezept ist ein praktisches Beispiel für einen Algorithmus. Es ist eine Schritt-für-Schritt Anleitung, lässt aber persönliche Präferenzen und Freiheiten zu, da man bestimmte Zutaten auch durch andere Zutaten ersetzen kann, und nicht jeder Koch unter einer Prise Salz dieselbe Menge an Salz versteht.
Beim maschinellen Lernen ist ein Algorithmus eine systematische und geordnete Abfolge von Schritten, bzw. Anweisungen an einen Computer, die präzise ausgeführt werden müssen, um eine bestimmte Aufgabe zu lösen.
Modell
Während des Trainings wird der Algorithmus so lange angepasst, bis er in der Lage ist, korrekte Vorhersagen zu nicht in den Trainingsdaten enthaltenen Daten zu treffen. Ein Modell ist also das Ergebnis des maschinellen Lernens in Form eines parametrierten Algorithmus.
Beispiel für den Zusammenhang zwischen Algorithmus und Modell:
Ein Regressionsalgorithmus bestimmt die Koeffizienten k und d der zugrunde liegenden Regressionsgeraden vom Typ \(y = k \cdot x + d\) , für ein linearen Modell, aus einer Vielzahl von Punkten, die in einem xy-Koordinatensystem eingetragen sind.
Das lineare Regressionsmodell liegt in Form einer Geradengleichung \(y = 2 \cdot x + 0,5\) vor, welche die Beziehung zwischen der Eingangsvariable (x) und der Zielvariable y beschreibt.
Verarbeitungseinheiten eines LLMs
Prompt
So wie es uns von der Google-Suche vertraut ist, gibt man in den Eingabe-Slot von ChatGPT und Bard eine Suchanfrage, die Prompt genannt wird, ein. Der Prompt steuert wie das LLM den Text verarbeitet.
Im Unterschied zur Google-Suche formuliert man sein Ansinnen aber nicht stichwortartig, sondern in mehreren ganzen natürlich-sprachigen Sätzen. Stellt man eine Frage in deutscher oder englischer Sprache, so erfolgt die Antwort in der entsprechenden Sprache. Der Eingabe kann und soll auch Hinweise auf die Zielgruppe der Antwort mitgeben (etwa „schülergerecht“, „in 5 Bullet Points“, …).
Man kann ChatGPT auch bitten eine konkrete Sichtweise einzunehmen ("Wie hätte Newton das erklär") oder ein Sprachniveau (A1, also einfachstes Vokabular) einzuhalten. Für jedes neue Thema sollte man einen separaten Chat anlegen, damit die KI den Überblick behält, worum es thematisch geht.
Token
Der mittels Prompt eingegebene Text wird in einzelne Text-Fragmente, sogenannte Token zerlegt. Ein Token ist zugleich die kleinste Einheit in der ChatGPT Texte verarbeitet und sie sind auch die Basis für die Verrechnung bei Bezahlmodellen. ChatGPT versteht Eingaben auf Basis von Token und generiert Ausgaben auf Basis von Token. Ein Token kann dabei ein Satzzeichen, der Teil eines Worts, ein einzelnes Wort oder eine ganze Phrase umfassen.
Token-Vektor
Jeder Token aus den Trainingsdaten wird mittels eines Zahlenvektors in einem virtuellen multi-dimensionalen Vektorraum dargestellt. Das ist extrem aufwändig!
Die Vektoren sind so konzipiert, dass sie semantische Informationen über den Token enthalten und es dem Transformer (das T in GPT) ermöglichen, Beziehungen zwischen den Tokens zu modellieren. Auf Basis der Token-Vektoren kann der Transformer komplexe sprachliche Muster erkennen. Die Vektoren können dazu verwendet werden, um mathematische Operationen auf den Token anzuwenden, wie das Berechnen von Ähnlichkeiten zwischen Token oder das Generieren von Text basierend auf Token unter Berücksichtigung der Wahrscheinlichkeit für eine insgesamt intelligente Antwort über mehrere Sätze hinweg.
Chat
Ein kontext-umfassender Chat kann nur eine endliche Anzahl an Token umfassen. D.h. ChatGPT verliert nach dem Überschreiten einer vorgegebenen Anzahl an Token (4096 Token bei Version ChatGPT-3.5) den “roten Faden“ in einem Chat. D.h. es weiß nicht mehr, was es zuvor von sich gegeben hat. Das ist bei uns Menschen aber auch so …
Chatverlauf mit durchgängigem Kontext
Die vergangenen Anfragen bleiben in der linken Bildleiste von ChatGPT erhalten und können jederzeit im Rahmen dieses Chats fortgeführt werden. Will man das Thema wechseln, so bietet sich der Button „New Chat“ an, wodurch man einzelne Chats thematisch fokussieren kann.
Man spricht vom Kontext des Chats, der es ChatGPT ermöglicht zu wissen um welches übergeordnete Thema es bei einer Abfolge von Anfragen – dem Chatverlauf - geht.
ChatGPT und Gemini
Das Jahr 2023 wird wohl in die Geschichte eingehen, als das Jahr, in dem generative künstliche Intelligenz nicht mehr nur ein Thema für IT-Profis ist, sondern in der breiten Masse, der nicht technikaffinen Internetnutzer, angekommen ist.
11.2022 wurde ChatGPT von OpenAI öffentlich verfügbar und innerhalb von nur 5 Tagen erreicht ChatGPT eine Million Nutzer. Dafür hat Instagram 2,5 Monate benötigt, Facebook immerhin 10 Monate und Twitter gute 2 Jahre.
10.2023 machte Google seine KI namens Bard öffentlich verfügbar.
ChatGPT und Gemini sind beide sprachbasierte generative KIs, bei der eine künstliche Intelligenz vom Typ „Large Language Model (LLM)“ mit dem Nutzer unter Zuhilfenahme einer Chatoberfläche kommuniziert. Sie unterscheiden sich aber auf Grund ihrer Architektur.
ChatGPT
ChatGPT basiert auf der GPT-Architektur, welche von OpenAI entwickelt wurde. GPT-3 basiert auf 175 Milliarden und GPT-4 auf 100 Billionen Parametern. GPT gilt als Vielseitiger als Gemini.
- Das Chat in ChatGPT steht für eine Mensch Maschine Schnittstelle (MMI), die einen Dialog zwischen Nutzer und KI in Form von Frage und Antwort ermöglicht.
ChatGPT und Bard kommunizieren beide mittels Chats. - Das „G“ in ChatGPT steht für Generative KI, was bedeutet, dass die KI eigenständige Texte erstellen (also „generieren“) kann, die sehr wahrscheinlich eine sinnvolle Antwort auf eine textuelle Eingabe bzw. Fragestellung darstellen.
ChatGPT und Gemini sind beide generative KIs. - Das „P“ in ChatGPT steht für Pre-Trained, was bedeutet, dass die KI vorab mit einer gigantisch großen Anzahl an Textinhalten bzw. Bildern aus Datenbanken trainiert wurde. Während des Trainings baut die KI einen multi-dimensionalen Vektorraum auf, in dem Token mittels Vektoren platziert werden.
ChatGPT und Gemini sind beide pre-trained. - Das „T“ in ChatGPT steht für Transformer. Transformer-Architiektur bezeichnet eine spezielle Architektur eines neuronalen Netzwerks, das in der Verarbeitung von natürlicher Sprache (Natural Language Processing, NLP) erfolgreich eingesetzt wird und welches von der Firma OpenAI entwickelt wurde.
- Zunächst werden in der Eingabe / Fragestellung („Prompt“ genannt), die für deren Beantwortung relevanten Daten mit Hilfe eines Aufmerksamkeitsmechanismuses erfasst.
- Auf Grund des Trainings hat sich das Modell selbst, also ohne menschliches Zutun, durch maschinelles Lernen, Muster und Beziehungen angelernt, um durch Gewichtungen bestimmen zu können, mit welchen Ausgaben es auf konkrete Eingaben reagieren soll.
- Auf Grund von Wahrscheinlichkeitsverteilungen erfolgt das Sampling, also die schrittweise Zusammenstellung der Antwort, bei der das wahrscheinlichste Wort der nächsten Ausgabe unter Berücksichtigung der bereits generierten Teilsätze so bestimmt wird, dass eine syntaktisch korrekte gut lesbare Antwort entstehen.
Die Stärke von ChatGPT liegt in der Fähigkeit textuelle Eingaben zu verstehen und zu beantworten. Darüber hinaus unterstützt ChatGPT-4 das Erstellen von Programmcode und die Fehlersuche in Programmcode. ChatGPT verfügt (Stand 02.2024) über keinen Zugriff auf aktuelle Webseiten. ChatGPT macht keine Angaben zur jeweiligen Quelle der Informationen. Ende 2023 hat OpenAI Verhandlungen mit Verlagen aufgenommen, um über die Kosten einer Lizenzierung von deren Inhalten für das Training von ChatGPT zu verhandeln.
Bing Chat
Bing Chat basiert auf der GPT-Architektur von OpenAI und auf dem Bildgenerator DALL-E3.
Bing Chat ist eine Erweiterung der Suchmaschine Bing von Microsoft und basiert auf GPT-4 von OpenAI, einem Unternehmen, an dem Microsoft umfangreich finanziell beteiligt ist.
Im Unterschied zu ChatGPT liefert Bing Chat sehr wohl Angaben zu den Quellen, mitunter ist das auch maths2mind.com. Der Nutzer kann zwischen den Konversationsstilen Precise, Balanced und Creative wählen. Die Wahrscheinlichkeit dass Bing Chat „halluziniert“ ist auf Grund der bestehenden Verbindung zu den Quellen geringer als bei ChatGPT.
Bing Chat bietet auch die Möglichkeit der Bildgenerierung mittels DALL-E.
Microsoft Copilot
Microsoft Copilot wiederum basiert auf Bing Chat.
Microsoft Copilot macht die Funktionen von Bing Chat außerhalb der eigentlichen Bing Suche, etwa in Microsoft Programmen wie Word verfügbar und erfordert Windows 11 mit mindestens dem 22H2-Update.
Google Bard
Bard basiert auf der LaMDA-Architektur, welche von Google AI bzw. Alphabet entwickelt wurde. Die LaMDA-Architektur wurde speziell für Dialoganwendungen, einschließlich Sprachübersetzungen, entwickelt.
So wie auch ChatGPT verwendet auch Bard Chats, ist eine generische KI und wurde vorab-trainiert, ist also pre-trained. Bard arbeitet aber nicht mit der GPT-Architektur, sondern mit der LaMDA Architektur. Bard basiert auf 137 Milliarden Parameter. LaMDA verwendet so wie GPT Token und eine Transformer-Architektur, die auf „Aufmerksamkeit“ basiert. Darüber hinaus verwendet LaMDA noch semantische Einbettungen, das sind zusätzliche Vektoren, welche die Bedeutung von Wörtern und Phrasen darstellen. Zudem hat LaMDA Zugriff auf weitere Google Dienste wie Google Search und Google Assistant.
LaMDA steht für Language Model for Dialog Applications
Google Gemini
Google AI verfügt neben der LaMDA-Architektur auch über die Gemini-Architektur, welche von Google Brain und Deepmind entwickelt wurde. Es gibt sie in den Varianten Ultra, Pro und Nano, die sich in der Anzahl der Hidden Layer der zugrunde liegenden neuronalen Netze unterscheiden. Bei Gemini handelt es sich um ein besonders effizientes LLM. Bard-Advanced basiert auf der Gemini-Pro Variante. Lokal auf Smartphones soll Gemini Nano zum Einsatz kommen. Für industrielle Anwendungen, etwa die Wettervorhersage, ist Gemini-Ultra vorgesehen.
Die Gemini-Architektur ist eine Multi-Model-Architektur, die mehrere Sprachmodelle mit unterschiedlichen Stärken und Schwächen kombiniert. Sie ist vielseitiger als die rein dialogorientierte LaMDA-Architektur. Die Gemini Architektur ist von Grund aus auf Multimodalität ausgelegt, d.h. sie kann mit Text, Bildern, Videos, Tönen und Code – mittels Alphacode 2 - umgehen.
Der Bildgenerator basiert auf Imagen-2. Haben Bildgeneratoren wie Midjourney bisher nach dem One-Shot-Verfahren Bilder aus einem Rauschen heraus generiert, kann man nun durch nachfolgende Befehle weitere Veränderungen am bereits generierten Bild vornehmen, ohne dass das Bild erneut aus einem Rauschen neu erzeugt wird. In die Bilder ist ein unsichtbares Wasserzeichen integriert, welches auf der Technologie SynthID basiert.
Gemini verfügt auch über die Fähigkeit durch den Nutzer hochgeladene Bilder verbal zu beschreiben und optisch Texte in Bildern zu erkennen (OCR – Optical Character Recognition).
Der Einstieg in ChatGPT
Sie können ChatGPT nutzen, indem Sie in ihrem Browser die URL „chat.openai.com“ aufrufen und sich dort mit Ihrem Google User anmelden. Du arbeitest also nicht anonym.
- ChatGPT-3.5
Dann steht Ihnen die Version GPT-3.5 kostenlos und die Version GPT-4 gegen ein monatliches Entgelt zur Verfügung. ChatGPT 3.5 gibt den September 2021 als letztes Update für den trainierten Wissensstand an und arbeitet mit einem Limit von 4096 Token (Textfragmenten), was einem Chatverlauf von wenigen tausend Worten entspricht. - ChatGPT-4
Das kostenpflichtige ChatGPT 4 soll einen Chatumfang von ca. 50 Seiten umfassen und zusätzlich Bilder verarbeiten. Die Benutzeroberfläche wird nicht nur geschriebene Chats umfassen, sondern auch Spracheingabe (Voice-to-Text mittels Whisper) und Sprachausgabe (Text-to-Speech). Ebenfalls in Arbeit ist die Interpretation von Text, der in Fotos enthalten ist, als zusätzliche Eingabemöglichkeit. Zusätzlich gibt es zu ChatGPT-4 sogenannte Plug-Ins, die etwa die Anbindung des Computer Algebra Systems von Wolfram Alpha ermöglichen, wodurch ChatGPT auf tatsächlich rechnen kann
Der Einstieg in Gemini
Sie können Gemini nutzen, indem sie in ihrem Browser die URL „gemini.google.com“ aufrufen und sich dort mit Ihrem Google User anmelden. Auch hier arbeitest du nicht anonym.
Derzeit (02.2024) ist Gemini kostenlos.
Der Einstieg in Bing-Chat
Sie können Bing-Chat nutzen, indem sie in ihrem Browser die URL „bing.com“ aufrufen und sich dort mit Ihrem Microsoft Konto anmelden. Auch hier arbeitest du nicht anonym.
Derzeit (02.2024) ist Bing-Chat kostenlos.
Der Einstieg in Microsoft Copilot
Sobald Copilot von Microsoft in der entsprechenden Region freigegeben ist, und man über die erforderliche Windows-Version verfügt, sieht man in der Taskleiste das entsprechende Symbol, zudem wird es als Pop-Up-Fenster am rechten Bildschirmrand angezeigt. Copilot soll zudem direkt in Programmen von Microsoft Office verwendbar sein. (03.02.204, auf unserem Win-11-PC noch nicht verfügbar).
Sie können Copilot nutzen, indem sie in ihrem Browser die URL "copilot.microsoft.com" aufrufen und sich dort mit ihrem Microsoft User anmelden. Auch hier arbeitest du nicht anonym.
Derzeit (03.2024) ist Copilot kostenlos.
Sprachbasierte generative KI und Mathematik
Sprachbasierte generative KIs, bei der eine künstliche Intelligenz vom Typ „Large Language Model (LLM)“ mit dem Nutzer unter Zuhilfenahme einer Chatoberfläche kommuniziert können ohne Plugin, also Schnittstellen zu einem externen CAS, grundsätzlich nicht rechnen!
Das kann sich auch so lange nicht ändern als LLMs auf stochastischen Modellen basieren. D.h. sie erzeigen eine Wahrscheinlichkeitsverteilung von möglichen Antworten. Dies ist bei Texten über mathematische Inhalte ausreichend, …
- Beispiel: Fragt man ChatGPT: „Wofür dient der Binomialkoeffizient“ so erhält man eine brauchbare Antwort: „Der Binomialkoeffizient, oft mit dem Symbol "n über k" oder "C(n,k)" dargestellt, ist eine mathematische Funktion, die in der Kombinatorik und Wahrscheinlichkeitstheorie weit verbreitet ist. Er dient dazu, die Anzahl der Möglichkeiten zu berechnen, k Elemente aus einer Menge von n Elementen auszuwählen, ohne die Reihenfolge zu berücksichtigen… Die Berechnung des Binomialkoeffizienten erfolgt in der Regel mithilfe der Kombinatorik-Formel: \(C\left( {n,k} \right) = \left( {\begin{array}{*{20}{c}} n\\ k \end{array}} \right) = \dfrac{{n!}}{{k!\left( {n - k} \right)!}}\) .
In der weiteren Antwort kommt aber auch der Begriff „Binomiales Experiment“ vor. Fragt man nach, ob ein „Binomiales Experiment“ dasselbe wie eine „Bernoulli-Kette“ ist, so verfängt sich ChatGPT in Widersprüchen ….
… nicht aber für Rechenaufgaben, die eine exakte Antwort benötigen.
- Beispiel: Fragt man ChatGPT „Wieviel ist 1+1?“, so erhält man als Antwort jenes Resultat, das ChatGPT am häufigsten in den Daten gefunden hat, mit denen es trainiert wurde: „1+1 ergibt 2“. Und müsste eigentlich hinzufügen: „Wahrscheinlich“.
Hat ChatGPT das Resultat aber noch nie gelesen, fängt es an zu raten: „Wieviel ist \root 5 \of {147,95} =“. Die Antwort lautet „Die fünfte Wurzel von 147,95 beträgt ungefähr 2,364“, was nicht wirklich brauchbar ist, denn: \(\sqrt[5]{{147,95}} \approx 2,71658\)
Rechenaufgaben erfordern ein Verständnis der zugrundeliegenden Mathematik, während KIs Muster in Trainingsdaten erkennen und daraus basierend auf einem Algorithmus ein Modell parametrieren, um neue Daten, ohne jegliches Verständnis der zugrundeliegenden Kausalitäten, – etwa von Gleichungen oder Formeln - zu generieren.
In dieser Mikro-Lerneinheit lernst du die Grundlagen der generative Fotobearbeitung und der generative Bildgenerierung mit Hilfe künstlicher Intelligenz kennen. Ausgehend von der Retouche analoger Fotos durch "nachbelichten" oder "abwedeln", kommen wir zum "photoshoppen" digitaler Fotos, damit diese am Smartphone "instagrammable" fürs soziale Netzwerk werden, wodurch leider unrealistische Standards etabliert werden.
Als die automatische Trennung vom Motiv im Vordergrund zum Himmel im Hintergrund durch leistungsfähige Computerprogramme möglich wurde, war der Grundstein für die generative Fotobearbeitung gelegt. Plötzlich konnten beliebige Bildteile markiert und gelöscht oder ausgetauscht werden. Durch generatives Erweitern wurden fehlende Bildteile durch die KI ergänzt.
Den derzeit aktuellen Entwicklungsstand dominieren generative Bildgeneratoren auf Basis "Text zu Bild". Diese Bildgeneratoren wurden mittels Diffusionsmethode, einer Anwendung maschinellen Lernens trainiert. Dabei beschreitet man den Weg vom klaren Foto mit textueller Beschreibung, über das Hinzufügen von Rauschen zu einem unkenntlichen Bild und wieder zurück zum klaren Foto durch Entrauschen. Das Entrauschen kann zweistufig erfolgen, wobei ein DAE (Denoising AutoEncoder) aus einem Ausgangsrauschen ein Bild niederer Auflösung generiert. Anschließend fügt ein VAE (Variational AutoEncoder) dem nieder aufgelösten Bild Details hinzu.
Beim maschinellen Lernen kommen neuronale Netze zum Einsatz. Wir gehen auf den Ansatz von der Firma OpenAI mittels CLIP (Contrastive Language-Image Pre-Training) ein, und erklären die Dual-Encoder-Architektur, mittels derer ein Bild-Encoder und ein Text-Encoder hochdimensionale vektorielle Darstellungen in einem Einbettungsraum erzeugen. Eine kontrastive Verlustfunktion sorgt dafür, dass im neuronalen Netz die Gewichte so angepasst werden, dass ähnliche Bild-Text-Paare im Einbettungsraum nahe beisammen zu liegen kommen.
Wir gehen auf die Eigenschaften eines optimalen Prompts ein und listen eine Auswahl an gängigen Tags auf. Den Abschluss bildet ein Test auf Praxistauglichkeit, bei dem wir unterschiedliche Bildgeneratoren die Darstellung des "Kampfes einer Mathematik-Studentin gegen ein aus Formeln und Termen zusammengesetztes Mathematik-Monster" generieren lassen.
Generative Fotobearbeitung und Bildgenerierung mittels KI
Foto-Retusche in der Zeit analoger Fotografie
Eine korrekte Belichtung und eine natürliche Farbwiedergabe, sowie eine ansprechende Auswahl der Vergrößerung bzw. des Bildausschnitts gehörten schon immer zu den selbstverständlichen Elementen einer gelungenen Fotoausarbeitung.
Selbst in den Anfängen der analogen Fotografie ging man bald einen Schritt weiter, indem man versuchte durch Foto-Retusche eine nachträgliche Verbesserung oder Veränderung der eigentlichen Aufnahme zu erreichen. Die Möglichkeiten bei der Ausarbeitung der Fotos waren zunächst sehr beschränkt, etwa auf partielles Nachbelichten, um Bildteile abzudunkeln, oder „Abwedeln“, um Bildteile aufzuhellen.
Photoshoppen, damit Bilder "instagrammable" werden, in Zeiten der Smartphone-Fotografie
Durch die digitale Fotografie, speziell in Verbindung mit dem ersten mächtigen computerbasierten Fotobearbeitungsprogramm „Adobe Photoshop“, haben sich Anfang des 3. Jahrtausends die technischen Möglichkeiten der Bildbearbeitung dramatisch verändert. Seither sind bearbeitete Fotos allgegenwärtig und der Ausdruck „photoshoppen“ ist zur umgangssprachlichen Bezeichnung für nachträglich veränderte Fotos geworden.
Speziell als private Amateurfotos durch das Aufkommen des auf Video- und Foto-Sharing spezialisierten sozialen Netzwerks Instagram plötzlich weltweite Verbreitung fanden, mussten Fotos auch „instagrammable“ sein. Atemberaubende Landschaften, neiderweckende Architektur, attraktive Menschen mit porenlos reiner Haut in modischen Outfits, wurden zunehmend bedeutend und durch technische Manipulation, etwa mittels „Filter“, auch für absolute Laien am Smartphone machbar.
Mittlerweile werden diese Entwicklungen in der Fotografie als sozial und psychisch problematisch angesehen, da sie unrealistische Standards etablieren und zu Selbstzweifeln und Depressionen führen können.
Generative Fotobearbeitung mit Hilfe von KI
Den nächsten Schritt nach „photoshoppen“ und „instagrammablen“ Fotos liegt in der generativen Fotobearbeitung, die erst durch den Einsatz von künstlicher Intelligenz möglich wurde.
Den Anfang generativer Fotobearbeitung machte vermutlich das automatische Freistellen des Bildvordergrunds vom Himmel im Bildhintergrund. Dadurch wurde es möglich, das Motiv im Vordergrund selektiv zu bearbeiten, gefolgt vom Austausch des oft flauen Erscheinungsbilds des Himmels, gegen einen „dramatischen“ Himmel.
Dazu war es erforderlich, dass die Bildbearbeitungssoftware automatisch zusammenhängende Objekte erkennt, obwohl die Objekte durch den Bildbearbeiter nur grob mit transparenten Pinselstrichen händisch markiert werden. Besonders problematisch sind dabei durchscheinende Objekte wie die Äste, Zweige und Blätter eines Baums oder feine Strukturen in Haaren, die sich gegen den Hintergrund kaum abheben.
Generative Bildbearbeitung mit Adobe Photoshop, Adobe Lightroom, Luminar Neo oder ähnlichen Bildbearbeitungsprogrammen entwickelten sich weiter und ermöglichen es heute, nicht nur den Himmel, sondern beliebige Details aus einem Foto zu löschen oder auszutauschen. So kann ein störender Strommast in einer Landschaftsaufnahme gelöscht werden, oder statt einer Bierkiste schwimmt plötzlich eine Meeresschildkröte im heimischen Pool...
Generatives Erweitern ermöglicht es etwa ein 4:3 Foto auf ein 16:9 Foto zu erweitern, indem fehlende Bildinhalte durch die KI passend ergänzt werden. D.h. die KI generiert Bildinhalte, die vorher nicht da waren.
Generative Bildgeneratoren auf Basis von "Text zu Bild"
Erneut einen Schritt weiter gehen generative Bildgeneratoren auf Basis „Text zu Bild“. Bildgeneratoren wie Midjourney, DALL-E, Stable Diffusion und Firelfy wurden anhand von Millionen Bildern trainiert und ermöglichen es, ohne eigenem bildlichen Ausgangsmaterial ein neues Bild allein auf Basis einer verbalen Beschreibung zu erschaffen.
Diffusionsprozess: Vom klaren Bild übers Rauschen zum künstlich generierten Bild
Diffusionsmodelle
Generative Bildgeneratoren, die auf Diffusionsmodellen basieren, erzielen derzeit (03.2024) die besten Bilder, die nur auf einer verbalen Bildbeschreibung basieren. „Diffusion“ ist dabei ein Vorgehen beim Training der Bildgeneratoren, welches vom MIT (Massachusetts Institute of Technology) und Adobe unter der Bezeichnung „Stable Diffusion“ mit dem Ziel entwickelt wurde, realistische Bilder zu generieren.
Diffusion ist daher eine Form des maschinellen Lernens und nicht etwa eine Architektur, wie „Transformer“.
Schritt 1 – Foto taggen: Der maschinelle Lernprozess startet mit Fotos oder Bildern, deren Bildgegenstand von Menschen mittels Tags sprachlich beschrieben wurde. Man spricht in diesem Zusammenhang von "gelabeleten" also beschriebenen Daten. Ein „Tag“ oder "Label" ist in diesem Zusammenhang eine kurze prägnante Bildbeschreibung, die in ein NLP-System (Natural Language Processing) einfließt. Das ist insofern nichts Neues, als schon seit langem alle Bilder in umfangreichen Bilddatenbanken mit Hilfe von Tags auffindbar gemacht wurden. Mit Hilfe des NLP-Systems soll letztlich aus einer verbalen Bildbeschreibung wieder ein Foto generiert werden und zwar künstlich durch die generative KI.
Während des maschinellen Lernens benötigt man hunderte Fotos mit ein und dem selben Bildgegenstand (z.B.: eine Erdbeere). Der jeweilige Bildgegenstand unterscheidet sich dabei von Foto zu Foto durch Farben, Formen, Texturen, Muster, Linien, Flächen und durch „unerwünschte“ Bildinhalte. Die Darstellungen unterscheiden sich zusätzlich durch Kunststile und Bildkomposition. Die Fotos mit dem Bildgegenstand zum Tag „Erdbeere“ zeigen: Erdbeeren am Feld, einzelne Erdbeeren, in 2 Hälften geteilte Erdbeeren, Erdbeeren mit drei Blättern am Stiel, Erdbeeren mit Zucker in einer Schale, Erdbeeren in eine Kiste, Erdbeeren in einem Korb, Erdbeeren mit Schlagobers, Erdbeere auf einem Tortenstück, Erdbeeren mit Stroh-Unterlage am Feld. Es kommen auch Zeichnungen, Grafiken und Gemälde von Erdbeeren zum Einsatz.
Der Midjourney Befehl /describe erstellt einen Prompt auf Basis eines Bildes, welches durch den Nutzer zuvor hochzuladen wurde. Anhand dieser Beschreibung kann man lernen mit welchen Tags Midjourney ein Foto assoziiert.
Schritt 2 - Verrauschen: Jedem Foto wird nach und nach Rauschen hinzugefügt, bis das dargestellte Objekt für den Betrachter völlig unkenntlich ist. Dazu verändert ein Algorithmus die Auflösung, die Pixel selbst oder fügt Gauß’sches Rauschen hinzu. Der Zusammenhang mit den ursprünglichen Tag bleibt dabei im so trainierten Modell erhalten.
Schritt 3 - Rauschreduzierung: Im Umkehrprozess wird anschließend versucht, das Rauschen aus dem Bild zu entfernen, um ein neues Bild zu erzeugen. Dabei kommen Diffusions-Transformer auf Basis neuronaler Netze zum Einsatz. Dieser Prozess kann etwa zweistufig erfolgen:
- Schritt 3.1: Ein DAE (Denoising AutoEncoder) in Form eines neuronalen Netzes ist darauf trainiert, Rauschen aus einem anfänglichen Zufallsrauschen zu entfernen und ein, dem Prompt bzw. den Tags, entsprechendes Bild mit niedriger Auflösung zu generieren.
- Schritt 3.2: Ein VAE (Variational AutoEncoder) ebenfalls in Form eines neuronalen Netzes ist darauf trainiert, einem Bild mit niedriger Auflösung, auf Grund von Wahrscheinlichkeiten, Details hinzuzufügen, damit ein, dem Prompt bzw. den Tags, entsprechendes Bild mit hoher Auflösung generiert wird.
Wenn alles richtig funktioniert hat, liegt dann wieder ein hochauflösendes Bild gemäß den Vorgaben vom Prompt vor.
Den Trainingsbildern wurde also „Rauschen“ hinzugefügt und das Modell hat so gelernt, wie es umgekehrt aus Rauschen wieder ein Bild erzeugen kann, welches der vorgegebenen Bildbeschreibung entspricht.
Wenn Midjourney einen /imagine Befehl abarbeitet, kann der Nutzer zusehen, wie es mit Rauschen startet und iterativ immer mehr Bilddetails hinzufügt, sodass sich das Bild den Vorgaben aus dem Prompt annähert. Gibt man mehrfach die selbe Bildbeschreibung ein, entstehen immer neue Varianten des Bildes, da das Ausgangsmaterial „Rauschen“ mit all seinen Zufälligkeiten ist.
Wie wir gesehen haben, ist die Bildgenerierung schwieriger als die reine Sprachgenerierung. Es muss nämlich nicht nur der Prompt „verstanden“ werden, sondern zusätzlich ein Zusammenhang zwischen der sprachlichen Beschreibung (Tag oder Label) und den entsprechenden, von der KI generierten, grafischen Bildelementen hergestellt werden.
Auch hier kommt wieder maschinelles Lernen auf Basis eines neuronalen Netzes zum Einsatz. Die Technik die OpenAI für diesen Zweck entwickelt hat, nennt sich CLIP (Contrastive Language-Image Pre-Training). Dabei kommt eine Dual-Encoder-Architektur zum Einsatz. Dual Encoder bedeutet, dass separate Encoder für Bilder und Texte parallel zum Einsatz kommen:
- Der 1. Encoder ist ein Bild-Encoder. Dieser extrahiert während des Trainings relevante Merkmale aus einem Foto und erzeugt so eine hochdimensionale Vektordarstellung.
- Der 2. Encoder ist ein Text-Encoder. Dieser erzeugt aus der Bildbeschreibung, also den Tags, eine semantische Bildbeschreibung und erzeugt ähnlich wie ein LLM eine Vielzahl an Token-Vektoren. „Contrastive Language“ bedeutet, dass für jedes Bild mehrere Bildbeschreibungen eingegeben werden. Und zwar solche, die mit dem Bildinhalt übereinstimmen, und solche, die nicht mit dem Bildinhalt nicht übereinstimmen. Dies ermöglicht es dem neuronalen Netz das Gewicht je Kante für übereinstimmende Bild-Text Paare zu erhöhen bzw. bei nicht übereinstimmende Bild-Text Paaren zu verringern.
- Beide Vektordarstellungen werden in einen gemeinsamen Einbettungsraum vektoriell abgelegt. Dies ermöglicht es, die semantische Bedeutung von Texten mit visuellen Merkmalen in Bilddarstellungen parallel zu führen sodass zumindest die trainierte KI deren Beziehungen kennt. Diesen Einbettungsraum kann man sich zweidimensional wie ein Schachbrett vorstellen. Die Spalten sind mit den Text-Token und die Zeilen mit den Bild-Merkmalen beschriftet. In den Zellen finden sich die jeweiligen Bildinhalte. Diese Bildinhalte sind uns Menschen aber nicht mehr zugänglich. Man kann sie daher auch nicht kontrollieren oder manuell berichtigen, was bei der Erzeugung von Bildern zu unerwünschten Darstellungen, speziell bei Details wie Fingern führen kann.
- CLIP verwendet dabei eine kontrastive Verlustfunktion, die darauf abzielt, ähnliche Text-Bild-Paare im Einbettungsraum nahe beisammen zu positionieren, während unähnliche Paare von einander entfernt zu liegen kommen. Dies erfolgt wie bei neuronalen Netzen üblich durch Anpassung der Gewichte entlang der Kanten im neuronalen Netz durch die Encoder. Dabei kommt eine Distanzmetrik (z.B.: der euklidische Abstand) zwischen den Repräsentationen zum Einsatz. Der Verlust wird minimiert, indem positive Paare nahe bei einander liegen.
So können zu vorgegebenen Texten passende Bilder generiert werden (Midjourney: /imagine) oder zu vorgegebenen Bildern beschreibende Texte (Midjourney: /describe) erstellt werden.
Diffusionsmodelle sind sehr trainings- und rechenintensiv. Man benötigt für deren Training etwa einen Datensatz von 400 Millionen Bild- und Textpaaren. Die Qualität des generierten Bildes hängt von der Qualität, der im Einbettungsraum hinterlegen vektoriellen Text- und Bild-Zuordnung ab.
Prompt-Engineering
Es erfordert vom Nutzer viel Erfahrung den Prompt so zu erstellen, dass das erwartete Bildresultat generiert wird. Man nennt diesen Vorgang „Prompt Engineering“. Diese Problematik wird noch verschärft, da sich die konkurrierenden Bildgeneratoren einerseits in deren Einbettungsraum, also im vektoriellen Text-Bild-Zusammenhang und andererseits in den verwendeten Trainingsdaten voneinander unterscheiden.
Wie wir bereits festgestellt haben wurden beim Training zur Beschreibung der Bildinhalte „Tags“ verwendet. Es ist daher naheliegend diese Tags auch in den Prompt einzubauen, um aus dem Ausgangsmaterial – einem Zufallsrauschen – ein gewünschtes Bild generieren zu lassen.
Ein optimaler Prompt sollte folgende Eigenschaften haben:
- Stichwortartige, klare und präzise verbale Beschreibung des Bildinhalts, getrennt nach Hauptmotiv und Umfeld.
- Angaben, wie man das Bild ohne KI erzeugen hätte können.
Nachfolgend eine Auflistung gängiger Tags, die sich für Prompt Engineering anbieten. Die Aufzählung erhebt keinerlei Anspruch auf Vollständigkeit und soll ausschließlich inspirieren!
Art Styles (Kunstrichtungen)
- Painting (Malerei)
- Renaissance (Renaissance): Gekennzeichnet durch realistische Proportionen, Perspektive und klassische Themen. Stil der im 15. und 16. Jahrhundert vorherrschte. Markiert Übergang vom Mittelalter zur Frühen Neuzeit
- Baroque (Barock): Verschnörkelter, pompöser, reich verzierter Stil, der im 17. und 18. Jahrhundert vorherrschte.
- Impressionism (Impressionismus): Fängt flüchtige Momente, Licht und Atmosphäre mit lockerer Pinselführung ein. Stil des 19. Jahrhunderts.
- Expressionism (Expressionismus): Drückt Gefühle durch verzerrte, grobe Formen und lebhafte, ungemischte, kontrastreiche Farben aus. Stil des ausgehenden 19. Jahrhunderts
- Cubism (Kubismus): Stellt Objekte künstlich auf geometrischen Formen wie Würfel reduziert dar. Stil Anfang des 20. Jahrhunderts
- Surrealism (Surrealismus): Bekannt für traumhafte, unlogische Kompositionen mit Träumen, Visionen, Rauschzuständen. Stil Mitte des 20. Jahrhunderts.
- Traditional Drawing and Painting (Traditionelles Zeichnen und Malen)
- Japanese Ink (Japanische Tusche): Minimalistische, fließende Tuschpinselführung.
- Watercolor Sketch (Aquarell-Skizze): Transparente, zarte Aquarellstudie.
- Pastel Drawing (Pastell-Zeichnung): Weiche, kreideartige Farben auf Papier.
- Oil Painting (Ölmalerei): Reichhaltige, strukturierte Gemälde mit Pigmenten auf Ölbasis.
- Modern and Experimental Representations (Moderne und Experimentelle Darstellungen)
- Hyperrealistic (Hyperrealistisch): Über die Realität hinausgehende idealisierte hochauflösende Darstellung eines tatsächlich existierenden Objekts.
- Fantasy (Fantasie): Fantasiewelten, Kreaturen und magische Elemente.
- Surreal (Surreal): Traumhaft, mit unerwarteten Kombinationen von Objekten und deren Verzerrungen.
- Contemporary (Zeitgenössisch): Reflektiert aktuelle Zeiten und deren Themen
- Daguerreotype Daguerreotypie: (1830) Frühes fotografisches Verfahren mit einem ausgeprägten Vintage-Look.
- Abstract (Abstrakt): Einfache Formen, Farben und Kompositionen. Objekte auf deren Grundelemente reduziert
Pixel Art (Pixel Kunst): Pop-Art, mit grellen sich wiederholenden Mustern mit erkennbaren Bildpunkten im Stil von Andy Warhol - Anime Art (Japanische Animation): Farbenfrohe japanische Darstellung in Animationsfilmen.
- Manga Art (Japanische Comic): Schwarz-Weiße japanische Darstellung in Comics
- Typography Style (Druckkunst): Gut lesbare, optisch ansprechende Darstellung von Schriften und Layouts, soll das Erfassen der Bedeutung erleichtern.
- Graffiti Art (Ästhetische Schreibkunst): Es steht die Darstellung der Schrift im Vordergrund und nicht die Bedeutung oder der Inhalt
- Dripping Painting (Tropfende Malerei): Abstrakte Kunst mit scheinbar noch flüssiger oder tropfender Farbe.
- Digital Illustration (Computerbasierte Darstellungen)
- Infographic (Informationsbezogene Darstellung): Klare, sachliche, informative Visualisierungen für Daten und Konzepte
- 2D Illustration (Zwei-Dimensionale Darstellung): Darstellung in der Ebene
- 3D Illustration (Drei-Dimensionale Darstellung): Räumliche Darstellung
- Isometric Drawing (Grund-, Auf- und Kreuzriss): Geometrisch exakte 3D-Darstellung
- Photography (Fotografie)
- Cinematic Scene (Filmische Szenerie): Erzeugt eine filmähnliche Qualität, oft mit dramatischer Beleuchtung.
- Portrait (Porträtfotografie): Konzentriert sich auf das Einfangen des Wesens einer Person.
- Documentary (Dokumentarfotografie): Nimmt Ereignisse, Menschen und Orte aus dem wirklichen Leben auf.
- Street Photography (Straßenfotografie): Unverfälschte Aufnahmen des täglichen Lebens in städtischen Umgebungen.
- Landscape (Landschaften): Zeigt natürliche Landschaften und Umgebungen.
- Architectural Photography (Architekturfotografie): Gebäude und städtische Umgebung stehen im Fokus. Spiel mit Licht, Linien, Formen und Himmel
- Fashion (Mode): Hebt Kleidung, Accessoires und Stil hervor.
- Glamour (Glamouröse Fotografie): Betont Eleganz und Verführung.
- Double Exposure (Doppelbelichtungen): Übereinanderliegende Bilder für einen surrealen Effekt oder zur gleichzeitigen Darstellung zeitlich gestaffelter Vorgänge
- Long Exposure (Langzeitbelichtung): Bedeutet, dass ein Bild über mehrere Sekunden hinweg belichtet wird. Erzeugt Bewegungsunschärfe, Lichtspuren und weich fließendes Wasser
- Vintage (Nostalgisch): Greifen den Look vergangener Zeiten auf, verblasste Farben in sepia Tönen mit körniger Textur
- Polaroid Art: (Sofortbild): Ahmt das Aussehen von Polaroid-Sofortbildern nach.
- Genre (Klassifikation mit Bezug zum Handlungsaufbau):
- Film Noir (Düsterer Look): Düstere, geheimnisvolle Szenerie, oft mit Verbrechensthematik.
- Horror (Horror): Angst und Entsetzen auslösend
- Western (Western): Ein edler, wohlgesonnener Held stemmt sich gegen eine Überzahl an Bösen in der Landschaft des amerikanischen Westen.
- Fantasy (Fantasy): Magische und übersinnliche Schauplätze.
- Romantic (Romanitk): Zelebriert Liebe und Gefühle.
- Drama (Drama): : Intense and emotional narratives.
- Animation (Animation): Bewegung entsteht durch eine Abfolge von Zeichentrick- oder Computerbildern, oder durch Stop-Motion-Animationen
- Science-Fiction (Science-Fiction): Wissenschaftsnahe spekulative Auseinandersetzung mit möglichen Zukunftsszenarien.
- Thriller (Thriller): Spannend und fesselnd mit Elementen die die Betrachter erschrecken.
- Mystery (Mystery): Fesselnde Rätsel und Geheimnisse, oft mit offenem Ende
- Documentary (Dokumentarisch): Ereignisse und Geschichten aus dem wirklichen Leben.
- Historical (Historisch): Schilderung vergangener Epochen und Ereignisse und deren Bezug zur Gegenwart
- Camera Equipment (Kameragehäuse)
- Hasselblad X2D: Modefotografie mit 100 MP Sensor für höchste Bildqualität bei starken Vergrößerungen
- Phase One XF: Fotoapparat für Landschaftsfotografie, bei der man Details heraus-vergrößern kann
- Canon EOS R3: Reportage und Sport wo nicht viel Zeit zum Scharfstellen ist
- DJI Phantom 4: Luftaufnahmen und zur Verfolgung bewegter Objekte
- Nikonos V: Unterwasseraufnahmen und an regengepeitschten oder klimatisch extremen Orten, mit Wechselobjektiven
- GoPro Hero: Selfie-Action-Aufnahmen und Abenteuersport
- Polaroid 635 Supercolor: Sofortbildkamera für nostalgischen Look
- Photo-Lenses (Objektive)
- 360-Degree-View Lens (Rundum-Objektiv): Erzeugt kugelförmig verzerrte Bilder mit einem Sichtwinkel im Bereich zwischen 180° und 360°
- Macro Lens (Makro-Objektiv): Eignet sich für extreme Nahaufnahmen im Maßstab jenseits von 1:1
- Fisheye Lens (Fischaugen-Objektiv): Starke tonnenförmige Verzerrung von Linien die nicht durch die Bildmitte laufen. Surreal anmutende Ansichten auch für Bildwinkel jenseits von 130°.
- Wide-Angle Lens (Weitwinkel-Objektiv): Weites Sichtfeld für Landschafts- und Architekturfotos. Rechte Winkel werden als rechte Winkel abgebildet. Große Tiefenschäfte und stellt Objekte im Vordergrund überproportional Groß dar.
- f=50mm (Normalobjektiv): Entspricht am ehesten dem menschlichen Sehen.
- f=85mm Lens (Portrait-Objektiv): Minimale Verzeichnung, natürlich wirkende Gesichtszüge, klare Trennung von Motiv und Bildhintergrund mit unverwechselbarem Bokeh
- Telephoto Lens (Teleobjektiv): Vergrößert weit entfernte Motive und komprimiert die Perspektive. Speziell Wildtier und Sportfotografie
- Photography Films (Filme aus der Zeit der Analogfotografie)
- Kodachrome 64: Diafilm mit satten und leuchtenden Farben mit ausgezeichneter Archivierungsstabilität. Entwicklung mit K-14 Prozess.
- Kodak Ektachrome: Tageslicht-Diafilm mit feiner Körnung, satten Farben und exzellenten Hauttönen. Entwicklung mit E-6-Prozess.
- Kodak Portra: Farbnegativfilm mit spektakulären Hauttönen für Portrait und Modeaufnahmen
- Kodak Gold: Farbnegativfilm für Privatanwender, der für seine warmen Farbtöne, den guten Belichtungsspielraum und den günstigen Preis bekannt war.
- Ilford HP5 Plus 400: Hochgeschwindigkeits-Schwarzweißfilm mit feinem Korn und hervorragender Schärfe
- Kodak Tri-X: klassischer Schwarzweißfilm mit einem düsteren Charakter, vielseitigem Kontrast
- Technicolor: Farbfilmverfahren, der 1930er und 1940er Jahre und für seine lebendige und stilisierte Farbpalette in klassischen Hollywoodfilmen bekannt.
- Polaroid SX-70: Produzierte farbige Sofortbilder mit Polaroid-Film, der sich durch sein einzigartiges quadratisches Format und seine weiche, verträumte Ästhetik auszeichnete.
- Kodak Aerochrome: Infrarotfilm, der surreale Landschaften mit leuchtenden Rot- und Rosatönen einfängt und häufig für künstlerische und experimentelle Fotografie verwendet wurde.
- Camera Sensor (Kamera-Sensoren)
- APSC Sensor (APSC Sensor) Hat gegenüber einem Vollformat-Sensor einen Cropfaktor von 1,6, um welchen sich die Brennweite des Objektivs scheinbar in Richtung Telewirkung verlängert. Preiswerter, da weniger Sensorfläche
- Full-Frame Sensor (Vollformat-Sensor): Sensorfläche wie Kleinbildfilm mit 36 x 24 mm.
- Aspect Ratio (Seitenverhältnis): Monitore weisen ein Seitenverhältnis von 16:9 oder 4:3 auf.
- Pixel Count (Pixelzahl): SD, Full-HD, 4k, 6k, 8k definiert Anzahl der Pixel je Zeile, Anzahl der Pixel in der Höhe errechnet sich aus dem Seitenverhältnis.
- Shutter-Speed (Belichtungszeit)
- Fast Shutter Speed (kurze Belichtungszeit): <1/500 sec; Ideal für Action Fotografie, friert den Moment ein
- Moderate Shutter Speed (mittlere Belichtungszeit): 1/100 sec: Ideal für Alltagsszenen, friert Bewegungen ein
- Slow Shutter Speed (lange Belichtungszeit): > 1/10 sec: Hervorragend geeignet, um ein Gefühl der Bewegung zu erzeugen, wie bei Bildern mit fließendem Wasser oder Lichtspuren.
- Aperture (Blende)
- Wide Aperture (Große Blendenöffnung): Niedrige Blendenzahl, etwa f/1,4 erzeugt eine geringe Schärfentiefe und lässt den Hintergrund verschwimmen (ideal für Porträts).:
- Narrow Aperture (Kleine Blendenöffnung): Hohe Blendenzahl, etwa f/16 erhöht die Schärfentiefe, sodass ein größerer Teil des Motivs im Fokus bleibt (Landschaftsfotografie).
- ISO value (Lichtempfindlichkeit):
- ISO 25: Am besten geeignet für helles Sonnenlicht, mit hervorragender Schärfe und Detailgenauigkeit.
- ISO 100: Ideal für Aufnahmen bei ausreichend Tageslicht.
- ISO 400: Kompromiss bei Belichtungszeit und Rauschen, nützlich in der Dämmerung
- ISO 6400: Ermöglicht kurze Belichtungszeiten in der Dunkelheit für Fotos ohne Stativ, erkauft wird das aber mit sichtbarem Bildrauschen.
- Lighting conditions (Lichtsituationen):
- Natural Daylight (Natürliches Tageslicht): Licht kommt von der Sonne
- Sunny (Sonnig): Helles Sonnenlicht bei klarem Himmel.
- Overcast (Bewölkt): Diffuses Licht aufgrund von Bewölkung
- Rainy (Regnerisch): Durch Regen gedämpftes Licht
- Foggy (Neblig): Geringe Fernsicht zufolge von Nebel
- Snowing (Schneefall): Schnee- und Eiskristalle machen das Licht diffus
- Sunlight (Sonnenlicht): grelles weißliches Licht von der Sonne
- Moonlight (Mondlicht): weiches, silbriges Licht vom Mond
- Firelight (Feuerlicht): Rötlich, warmes Licht durch ein Feuer
- Candlelight (Kerzenlicht): Gemütliches, flackerndes Licht von Kerzen
- Neon Light (Neonlicht): Grünliches Licht von Neonleuchten
- Low Light (Schwaches Licht): Gedämpftes Licht
- Low Key / High Key Lighting (Low / High Key Aufnahme): Dramatisch dunkle oder überstrahlend helle Lichtsituation
- Spot Lighting (Spot Beleuchtung: Auf einen bestimmten Bereich fokussierte Beleuchtung
- Softbox Lighting (Softbox Beleuchtung): Weiches, warmes, gleichmäßig flächiges Licht
- Light Through a Window (Lichteinfall durchs Fenster): Natürliches Licht, das durch Fenster einfällt.
- Colors (Farben):
- Colorized (Koloriert): Hinzufügen von Farbe zu einem Schwarz-Weiß- oder Graustufenbild.
- Vivid (Lebendige Farben): Intensiv helle und gesättigte Farben.
- Bright / Dark Colors (Helle / Dunkle Farben): Helle Farben sind leuchtend und hell, während dunkle Farben tief und gedämpft sind.
- Black and White (Schwarz-Weiß): Eine Graustufendarstellung ohne Farbe.
- Warm / Cold Colors (Warme / Kalte Farben): Warme Farben (Rot, Orange, Gelb) vermitteln Wärme, während kalte Farben (Blau, Grün, Lila) kühler wirken.
- Monochromatic (Einfärbig): Farbschema mit Variationen eines einzigen Farbtons.
- Polychromatic (Vielfärbig): Enthält mehrere unterschiedliche Farben.
- Faded Colors (Verblasste Farben): Gedämpfte oder verwaschene Farbtöne.
- Colorful (bunt): Reich an verschiedenen leuchtenden Farben.
- Inverted Colors (Invertierte Farben): Umkehrung der Farbwerte (z. B. weiß wird schwarz, blau wird gelb).
- Rainbow Colors (Farben des Regenbogens): Spektrum der Farben eines Regenbogens.
- Desaturated Colors (Ungesättigte Farben): Reduzierte Farbintensität.
- Tan (Bräune): Hellbrauner Farbton
- Aqua (Wasserfarben): Blau-grüner Farbton
- Azure (Azurblau): Hellblauer Farbton
- Lighting conditions depending on the time of day (Tageszeitabhängige Lichtsituationen):
- Night (Nacht): Dunkle Zeit, wenn die Sonne unter dem Horizont steht
- Sunrise (Sonnenaufgang): Der Moment, in dem die Sonne am Morgen zum ersten Mal über dem Horizont erscheint.
- Morning (Morgen): Nach dem Sonnenaufgang, durch zunehmendes Licht gekennzeichnet
- Golden Hour (Goldene Stunde): Magische Zeit kurz nach Sonnenaufgang oder kurz vor Sonnenuntergang, wenn das Licht warm und weich ist.
- Blue Hour (Blaue Stunde): Kurze Zeit vor Sonnenaufgang oder nach Sonnenuntergang, wenn der Himmel einen schönen blauen Farbton annimmt.
- Sunset (Sonnenuntergang): Der Moment, in dem die Sonne am Abend hinter dem Horizont verschwindet.
- Twilight (Dämmerung): Übergangsphase zwischen Tag und Nacht, die vor dem Sonnenaufgang und nach dem Sonnenuntergang stattfindet.
- Image Section (Bildausschnitt):
- Extreme Wide Shot (Weitwinkel): Ein weit gefasster Bildausschnitt eignet sich für Landschaften oder Architekturaufnahmen, bei denen das Hauptmotiv in einem großen Kontext gezeigt wird.
- Establishing Shot (Totale): Eine totale Aufnahme zeigt das eigentliche Motiv und dessen Umgebung.
- Full Shot (Halbtotale): Bei einer halbtotalen Aufnahme wird das Motiv in einem mittleren Ausschnitt gezeigt. Es wird ein Teil der Umgebung sichtbar, aber der Blick wird auf das Motiv gelenkt.
- American Cut (Amerikanische Einstellung): Bildausschnitt, wie er in Western für Cowboys beim Duell üblich ist. Die Person ist vom Kopf bis einschließlich der Oberschenkel sichtbar. Beliebt für Personenfotos auf Instagram.
- Medium Cut (Halbnah): Eine halbnahe Aufnahme zeigt das Motiv von etwa der Taille oder dem Hüftbereich aufwärts, es werden aber immer noch Teile der Umgebung sichtbar. Sie entspricht der Wahrnehmung eines einem gegenüber stehenden Gesprächspartners. Diese Einstellung ist auf Sozial-Media sehr beliebt. Der "Influencer" ist halbnah zu sehen, der einzigartige, beeindruckende, fotogene "Instagrammable Place" ist im Hintergrund erkennbar.
- Sholder Close Up (Nahaufname): Die Naheinstellung zeigt das Motiv in einem sehr engen Bildausschnitt. Menschen werden vom Kopf bis unterhalb der Brust dargestellt, so als würden sie von einem Bildhauer als Büste modelliert werden.
- Close Up (Großaufnahme): Eine Person ist vom Kopf bis zu den Schultern sichtbar, bzw. werden nur einzelne Körperteile, wie etwa die Hände sichtbar. Großaufnahmen eignen sich natürlich auch sehr gut für Gegenstände.
- Extreme Close Up (Detailaufnahme): Ein Detailausschnitt zeigt einen sehr engen Blick auf ein bestimmtes Detail oder einen kleinen Teil des Motivs, etwa die Armbanduhr eines Darstellers oder ein kleines Motiv auf einer bemalten Blumenvase.
- Italian Shot (Italienische Einstellung): Eine aus dem Film "Spiel mir das Lied vom Tod" bekannte Detailaufnahme, bei der ausschließlich die Augenpartie der Darsteller zu sehen ist. Die englische Bezeichnung lautet "Italian Shot".
- Bird’s View Shot (Vogelperspektive). Zeigt die Szene von oben, wie von einem fliegenden Vogel aus gesehen.
- Low Angle Shot (Niedriger Aufnahmewinkel): Sicht von unten nach oben, vermittelt das Gefühl von Macht und Dominanz.
- Moods (Stimmungen):
- Dark (Dunkel): Erweckt ein Gefühl von Geheimnis und Schatten.
- Bright (Hell): Strahlt Licht und Klarheit aus.
- Vibrant (Lebhaft): Strotzt vor intensiven Farben und Energie.
- Mystical (Mystisch): Rätselhaft, mit einem Touch vom Jenseits
- Romantic (Romantisch): Voller Emotionen, oft verbunden mit Liebe und Sehnsucht.
- Minimalistic (Minimalistisch): Auf die wesentlichen Elemente reduziert.
- Futuristic (Futuristisch): Zukunftsorientiert, mit einem Sinn für Innovation und Technologie.
- Meditative (Meditativ): Ruhig, beschaulich und besinnlich
- Seaside Ambient (Meeresambiente): Wellengeräuschen und salzige Luft.
- Underwater (Unterwasser): Unter Wasser, mit fließenden Bewegungen und gefiltertem Licht.
- Extraterrestrial (Außerirdisch): Fremd, jenseits unserer irdischen Welt.:
- Space (Kosmisch): Symbolisiert die unermesslichen kosmischen Weiten, übersät mit Sternen, Planeten und Galaxien.
- Desert (Wüstenhaft): Karge Landschaft mit Sand, Felsen und extremen Temperaturen.
- Forest (Wald): Ein üppiger, grüner Lebensraum, in dem es von Bäumen, wilden Tieren und Ruhe nur so wimmelt.
- Surface characteristics and Reflections (Oberflächeneigenschaften und Spiegelungen)
- Glossy, Shiny, Glare (Glänzend): Glatt und spiegelnd, mit hohem Glanz.
- Matte (Matt): Nicht reflektierend, mit einer stumpfen Oberfläche.
- Shimmering (Schimmernd): Funkelnd, wie Sonnenlicht auf Wasser.
- Reflective (Reflektierend): In der Lage, Licht oder Bilder zurückzustrahlen.
- Mirrored (Spieglend): Exakt reflektierend wie ein Spiegel.
- Satin (Satin): Weich und glänzend, mit einem subtilen Schimmer.
- Transparent (Transparent): Lässt das Licht klar und ohne Verzerrung hindurch.
- Translucent (Streuend): Lässt Licht durch, aber macht es streuend und diffus.
- Opaque (Undurchsichtig): Das Licht wird vollständig blockiert, so dass darunter liegende Objekte nicht sichtbar sind.
- Polarized (Polarisierend): Filtert Lichtwellen, um Blendung zu reduzieren und die Klarheit zu verbessern. Z.B.: weiße Wolken auf strahlend blauem Himmel
- Luminescent (Lumineszierend): Emittiert selbstständig Licht, wie bei Materialien, die im Dunkeln leuchten.
- Emotions (Emotionen):
- Fear (Angst): Eine Reaktion auf eine wahrgenommene Gefahr oder Bedrohung.
- Joy (Freude): Ein intensives Gefühl von Glück.
- Love (Liebe): Tiefe Zuneigung und Fürsorge für jemanden oder etwas.
- Hope (Hoffnung): Optimistische Erwartung eines positiven Ergebnisses.
- Anger (Wut): Starke Verärgerung oder Frustration.
- Sadness (Traurigkeit): Gefühl der Trauer oder des Kummers.
- Disgust (Abscheu): Abneigung gegen etwas Unangenehmes.
- Excitement (Aufregung): Vorfreude oder Begeisterung.
- Gratitude (Dankbarkeit): Aberkennung fremder Leistungen und deren Wertschätzung
- Guilt (Schuldgefühl): Emotionaler Kummer aufgrund von Fehlverhalten oder Bedauern.
- Envy (Neid): erlangen nach dem, was andere haben.
- Anticipation (Vorwegnahme): Gedankliche Erwartungshaltung, Vorgriff auf ein zukünftiges Ereignis
- Archetypes (Urbilder):
- Hero (Held): Mutige Figur, die sich Herausforderungen stellt und über Widrigkeiten triumphiert.
- Superstar (Superstar): Eine ikonische und gefeierte Person
- Princess (Prinzessin): Eine königliche und anmutige Figur, oft mit Märchen in Verbindung gebracht
- Rebel (Rebell): Ein Nonkonformist, der Autoritäten oder gesellschaftliche Normen herausfordert.
- Detective (Detektiv): Eifriger Ermittler, der Rätsel löst und die Wahrheit herausfindet.
- Explorer (Entdecker): Neugieriger Abenteurer, der nach neuen Horizonten und Entdeckungen sucht.
- Lover (LiebhaberIn): Eine leidenschaftliche und romantische Seele, die in Herzensangelegenheiten verwickelt ist.
- Outlaw (Gesetzloser): Ein Abtrünniger, der außerhalb des Gesetzes oder der gesellschaftlichen Konventionen agiert.
- Magician (Magier): Eine mystische und rätselhafte Figur mit übernatürlichen Fähigkeiten.
- Everyman (Jedermann): Eine gewöhnliche Person, die die allgemeine menschliche Erfahrung repräsentiert.
- Age group (Altersgruppe):
- Baby (Baby): Säuglinge.
- Infant (Kleinkind) Sehr junge Kinder
- Child (Kind): Eine junge Person vor Erreichen der Pubertät.
- Teenager (Teenager): Eine Person zwischen Kindheit und Erwachsensein, typischerweise im Alter von 13 bis 19 Jahren.
- Adolsescent (Heranwachsender): Eine Person, die sich im Übergangsstadium zwischen Kindheit und Erwachsensein befindet.
- Girl (Mädchen): Ein weibliches Kind oder eine junge Frau.
- Miss (Fräulein): Eine unverheiratete Frau
- Woman (Frau): Erwachsene weibliche Person
- Lady (Frau): Höfliche Anrede für eine elegante und beeindruckende Frau
- Boy (Junge): Ein männliches Kind oder ein junger Mann.
- Man (Mann): Erwachsene männliche Person
- Grandma (Großmutter): Eine liebevolle und erfahrene Großmutter.
- Grandpa (Großvater): Ein weiser und fürsorglicher Großvater.
- Senior (Senior) : Eine ältere Person, die oft mit dem Rentenalter in Verbindung gebracht wird.
- Elder Person (Ältere Person): Ein respektvoller Begriff für eine ältere Person, der ihre Weisheit und Erfahrung hervorhebt.
- Atributes of human body (Eigenschaften des menschlichen Körpers):
- Striking Eyes (Auffällige Augen): Augen, die aufgrund ihrer Intensität oder ihrer einzigartigen Merkmale die Aufmerksamkeit auf sich ziehen.
- Silky Hair (Seidiges Haar): Glattes und glänzendes Haar mit einer weichen Textur.
- Well-Styled Hair (Gut gestyltes Haar): Sorgfältig gepflegtes und arrangiertes Haar für ein gepflegtes Aussehen.
- Elegant Posture (Elegante Körperhaltung): Anmutige und ausgeglichene Körperhaltung.
- Natural Beauty (Natürliche Schönheit): Unverfälschte, echte Attraktivität.
- Inner Glow (Inneres Strahlen): Eine strahlende Qualität, die von innen kommt und Positivität und Selbstvertrauen widerspiegelt.
- Hourglass-Shaped Body (Sanduhrförmiger Körper): Eine weibliche Figur mit ausgeprägten Proportionen, die eine schmale Taille hervorheben.
- Athletic Physique (Athletischer Körperbau): Ein fitter und durchtrainierter Körper, der durch körperliche Aktivität entsteht.
- Charming Smile (Charmantes Lächeln): Ein warmes und fesselndes Lächeln, das das Gesicht erhellt.
- Strong Jawline (Kräftige Kieferpartie): Gut ausgeprägte Konturen entlang des Kiefers, die oft mit Selbstvertrauen verbunden sind.
- Characteristics of clothing (Merkmale der Kleidung):
- Stylish (Stilvoll): Ein modisches und gut abgestimmtes Erscheinungsbild.
- Elegant (Elegant): Anmutig, raffiniert und anspruchsvoll.
- Trendy (Trendig): Im Einklang mit den aktuellen Modetrends.
- Versatile (Vielseitig): Anpassungsfähig und für verschiedene Anlässe geeignet.
- Bohemian (Unkonventionell): Ungezwungen, freudig und unkonventionell. Inspiriert aus den 1960 Jahren.
- Flattering (Schmeichelhaft): Verstärkt das Erscheinungsbild und ergänzt die Gesichtszüge.
- Tailored (Maßgeschneidert): Individuell an den Körper angepasst und sorgfältig gefertigt.
- Transparent (Transparent): Durchscheinende Kleidung
- Cut out (Löchrig): Kleidung in der sich absichtlich Löcher befinden
- Famous Role Model (Berühmte Vorbilder):
Hier beginnt es rechtlich bedenklich zu werden, denn wenn die KI die nachfolgenden Personen und deren charakterisitische Eigenheiten tatsächlich kennt, um sie nachmachen zu können, stellt sich schnell die Frage, ob dieses Wissen aus urheberrechtlich unbedenklichen Quellen stammt und ob die Resultate rechtssicher verwendet werden dürfen.
-
- Painter (Maler): abhängig von persönlichen Vorlieben
- Graphic Designer (Grafiker): abhängig von persönlichen Vorlieben
- Photographer (Fotograf): abhängig von persönlichen Vorlieben
- Director (Regisseure): abhängig von persönlichen Vorlieben
- Set Designer (Bühnenbildausstatter): abhängig von persönlichen Vorlieben
- Film star (Filmstar): abhängig von persönlichen Vorlieben
- Superheroes (Superhelden): abhängig von persönlichen Vorlieben
- Cartoon Character (Zeichentrickfigur): abhängig von persönlichen Vorlieben
Test auf Praxistauglichkeit: Tech-Demo vom 28.03.2024
Erzeuge ein Foto wie folgt:
A 22-year-old mathematics student with long blonde hair, cut-out jeans, and a white T-shirt, elegantly posed, fights a math monster in the lecture hall with a ruler in hand. The monster is made up of mathematical terms and formulas. It takes the form of a dragon and attacks the student with its fiery eyes, bared teeth, and clawed claws. The mood is threatening and chaotic, but the student is determined to win the battle. Hyper-realistic cinematic 4k scenery, daylight, vibrant colors, medium shot, wide-angle shot.
Hier das Resultat von Copilot unterstütze von DALL·E
Bild

Hier das Resultat von Midjourney v 6.0:
Bild

Hier das Resultat von Adobe Firefly
Bild
